Qlikデータ統合の特徴
01
構築も変更も迅速、リアルタイム性を追求
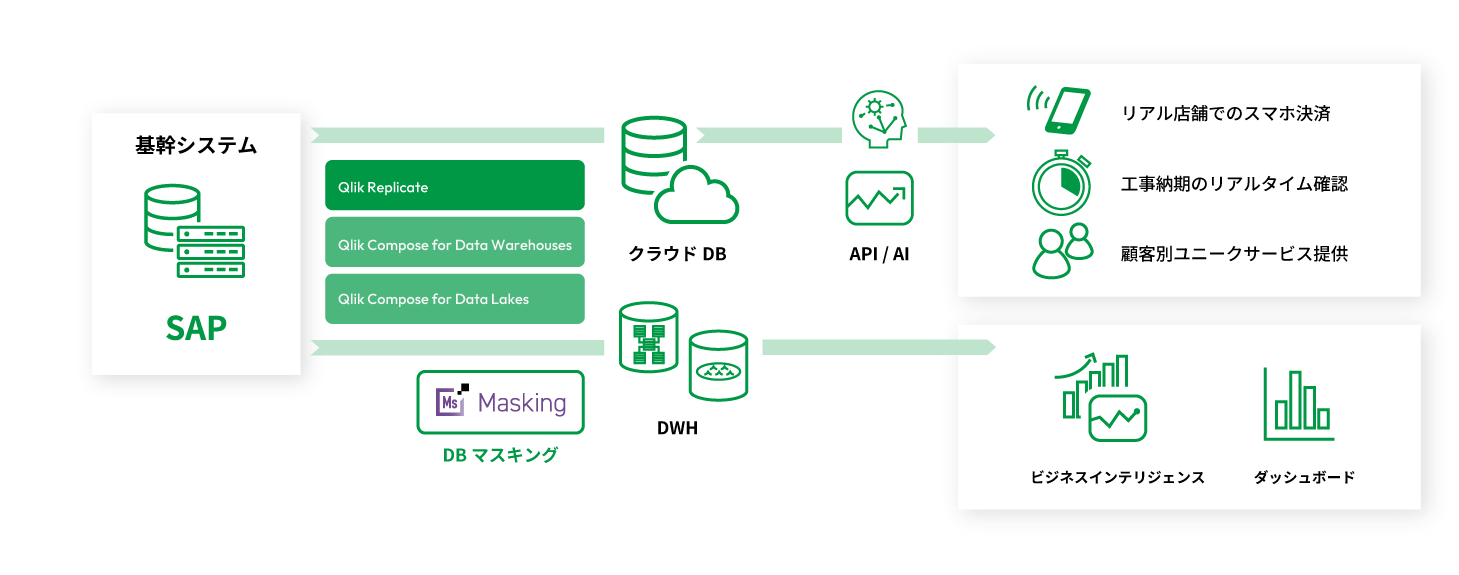
Qlikデータ統合は、ビックデータを持つエンタープライズDXに必須なリアルタイム性と拡張性を同時に提供します。Qlik Replicateはリアルタイムレプリケーションの自動構築を、Qlik
Compose for Data Warehousesはデータマートの設計、実装、更新の自動化による迅速な構築と変更を、 Qlik Compose for Data
Lakesはデータパイプラインを最速で作成。取り込んだ各データのメタデータを管理することで、分析への最短ルートを達成します。
POINT 1
データベースへ負荷をかけずに最新データを連携
エージェントレスで限りなく低負荷での運用が可能
POINT 2
迅速に連携対象データを追加・変更
高性能な独自CDC技術により、データ連携のリアルタイム性を向上
POINT 3
主要なデータベースをすべて網羅
異種間を含む様々な組み合わせに対応
02
Qlik Replicate
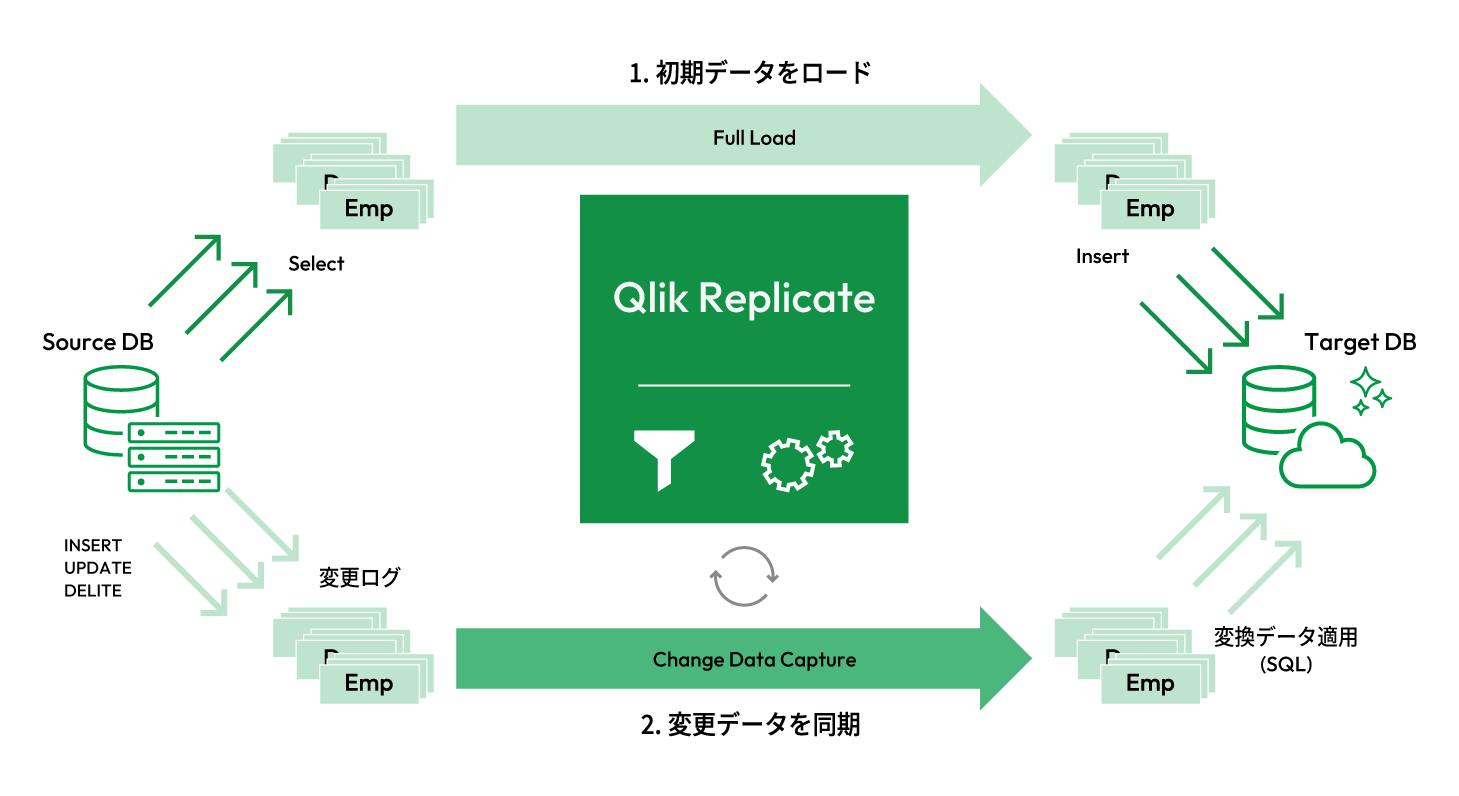
Qlik
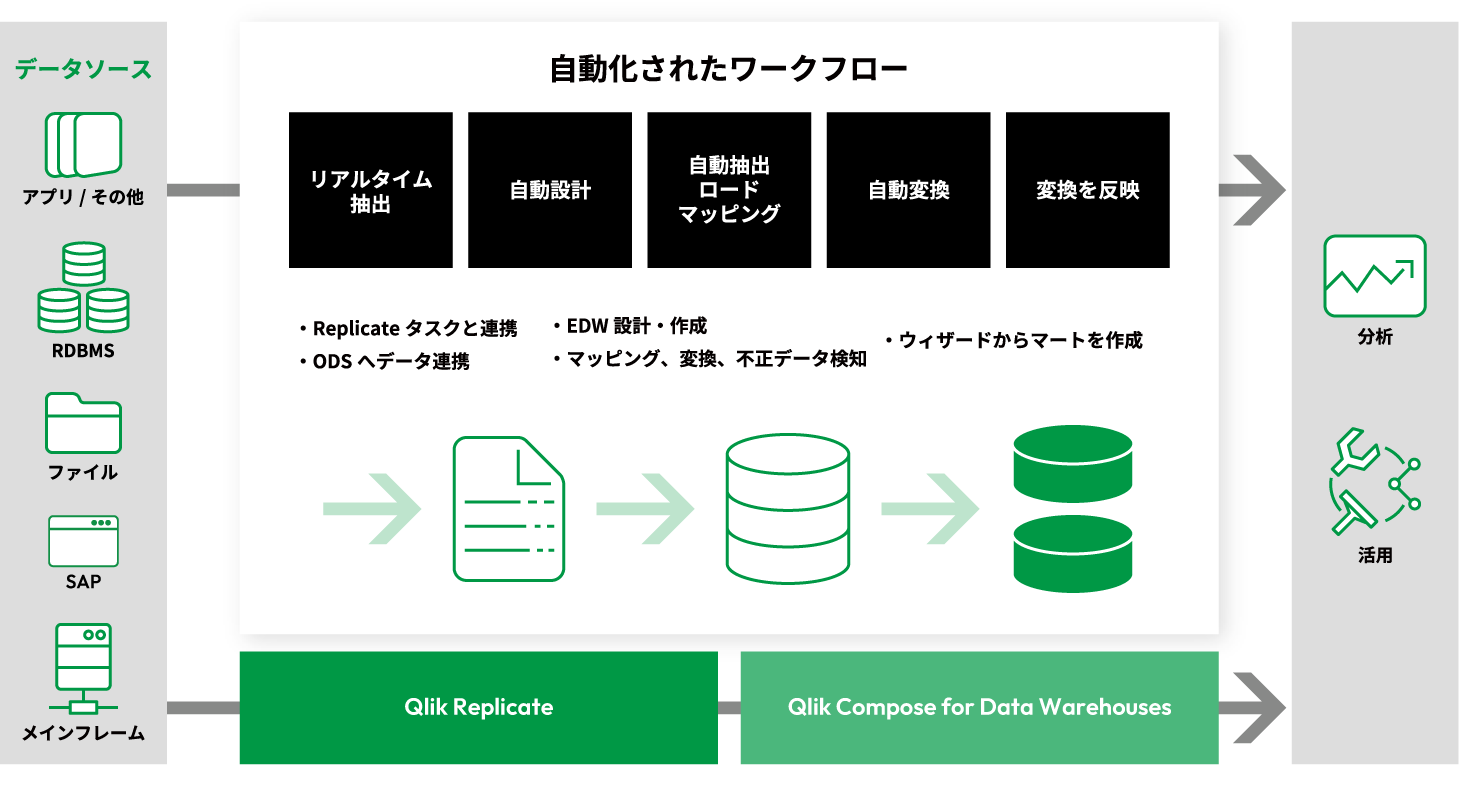
Replicateは異種データベースだけでなく、メインフレーム、SAP、Salesforceなどのデータを分析基盤などへリアルタイムに連携するレプリケーションソフトウェアです。多様化するデータ活用基盤の再構築において、既存システムに負荷をかけずに迅速で安全なデータ統合/移行が達成できます。ソースデータベースからターゲットデータベースへデータをコピーするのではなく、変更データログを読み込んで反映することで、限りなくリアルタイムに近いデータ連携を実現します。
03
Qlik Compose for Data Warehouses
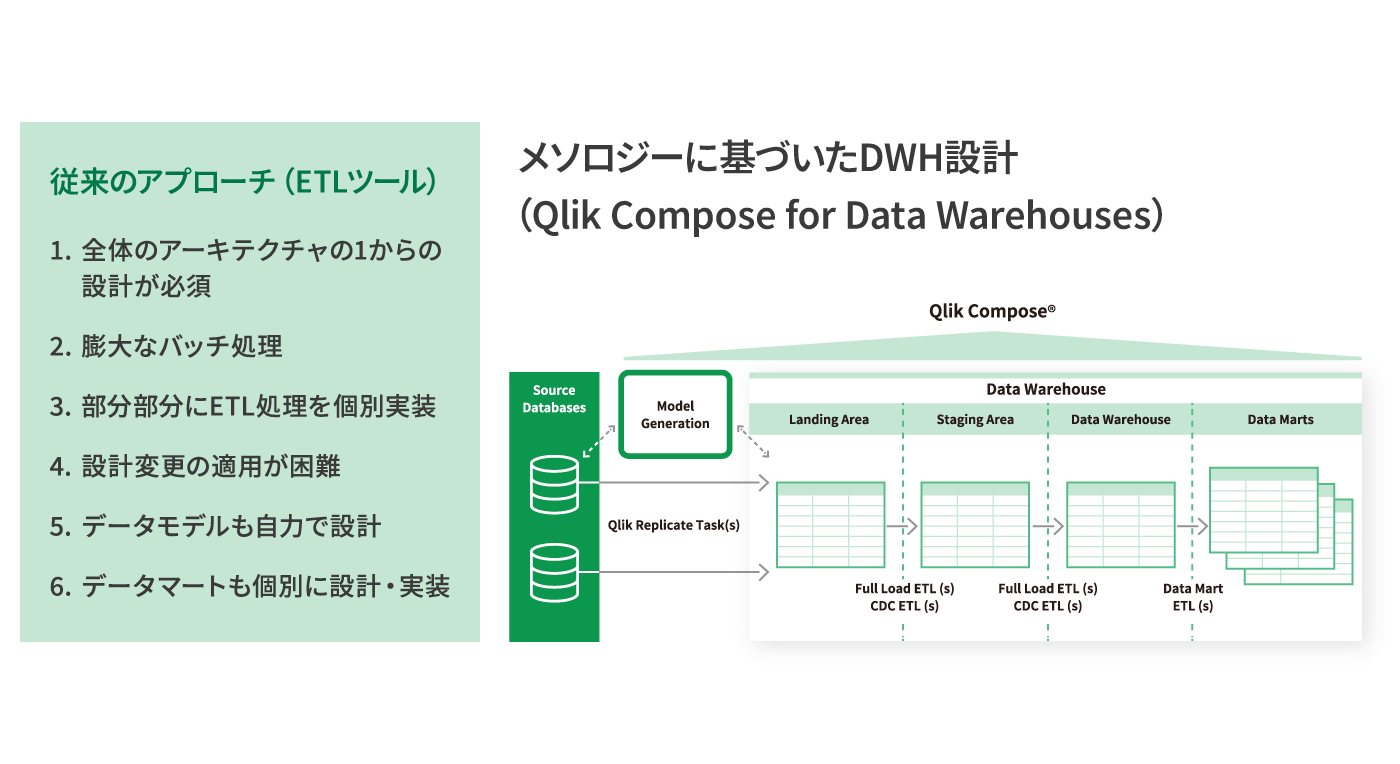
Qlik Compose for Data
Warehousesはリアルタイムデータウェアハウスを実現するためにデータマートの設計、実装、更新を自動化します。その特徴は、汎用的なETLツールとは決定的に異なるアプローチにあります。設計からコード生成、更新の適用まで、ベストプラクティスと実績のある設計パターンによって簡便化・自動化を実現。データウェアハウスの構築・管理をスピーディーなものに変えます。
04
Qlik Compose for Data Lakes
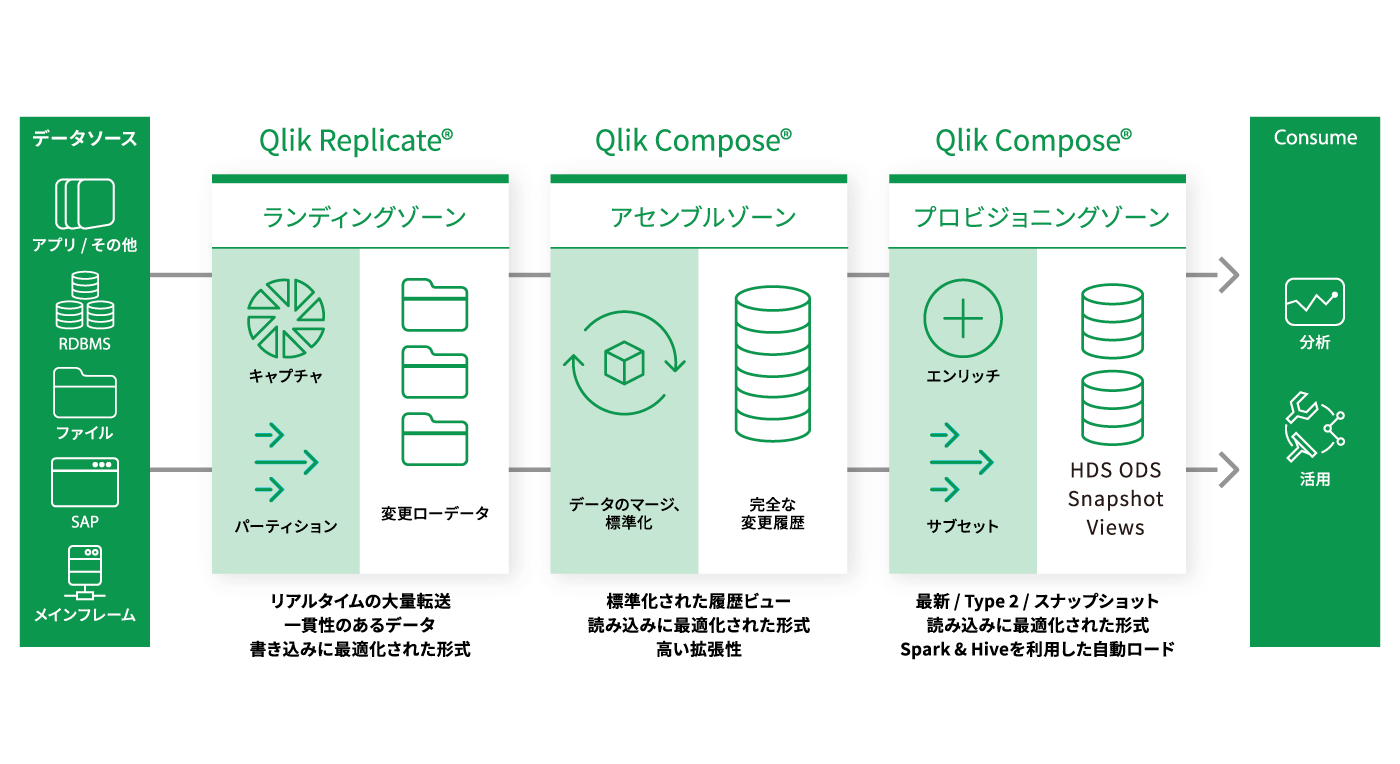
データレイクは様々な非構造化データをスキーマで事前定義することなく取り込める優位性がある反面、取り込んだデータの管理に困難が伴います。Qlik Compose for Data
Lakesは各データのメタデータを自動収集してカタログ化し、必要な時に最適なデータを取り出すことを可能にします。複雑なコーディングを排除して自動化することで、関連するリスク・コストを削減。データレイクの導入から成果を生み出すまでの時間を短縮します。



 Database
Database
 Mainframe
Mainframe
 SAP
SAP
 EDW
EDW
 Cloud
Cloud
 SaaS
SaaS
 Flat Files
Flat Files
 AWS
AWS
 Azure
Azure
 Google
Google
 Data Lake
Data Lake
 EDW
EDW
 Database
Database
 Streaming
Streaming
 SAP
SAP
 Flat Files
Flat Files