―― SingleStore はその夢を実現できるのか

執筆者:CSO 石川 雅也
前編では、HTAPという概念の歴史と、「HTAP対応」を名乗る現代の製品群を見てきた。TiDB、Snowflake UniStore、AlloyDB、Oracle、SAP HANA、SQL Serverと並べてみると、それぞれが抱える限界が浮かび上がった。「2エンジン協調」「後付けのトランザクション」「後付けの列ストア」「コスト問題」——どれも完全な解ではない。
では SingleStore はどうなのか。今回はいよいよ本題、SIGMOD*¹2022に採択された論文「Cloud-Native Transactions and Analytics in SingleStore」*² を読み解きながら、SingleStoreのアーキテクチャに踏み込んでいきたい。
前回は SingleStoreのブログと言いつつ SingleStoreのことを何も書いていないと指摘されたので(笑)、今回はSingleStoreのことをガッツリ書きます。
4. SingleStoreのアーキテクチャ:Universal Storage とは何か
4-1.MemSQL から SingleStore へ——設計思想の転換
前編のタイムラインで触れたように、SingleStore(旧 MemSQL)は 2011 年の創業当初、インメモリ行ストアと JITコンパイルによる超高速OLTPを強みとしていた。
しかし、「分析クエリも速くしたい」という要求にどう答えるか。初期の MemSQL が採った手は、行ストアとは別に列ストアを持つ「デュアルストレージ」だった。これは構造としては TiDBに近い。2エンジン協調、という意味で。
転機は 2020 年に発表した Universal Storage だ。
「行と列を、ひとつのテーブルで統合する」——言葉にすると単純だが、これが非常に難しい。前編で述べた「行指向 vs 列指向」という物理的な対立は、ストレージの根本設計に関わる問題だからだ。
4-2.Universal Storage の設計:RowSegment と ColumnSegment
SIGMOD 論文の中核をなすのが、Universal Storage の具体的な実装だ。ここを丁寧に読んでいく。
SingleStore のテーブルは、内部的に Segment(セグメント) という単位で管理される。このセグメントには2つの形態がある。
RowSegment(行セグメント):
新しく書き込まれたデータは、まずメモリ上の行指向ストアに入る。スキップリストを用いたロックフリーなデータ構造で、高頻度の INSERT/UPDATE/DELETE を高速に処理できる。MVCC(Multi-Version Concurrency Control)*³により、読み取りも書き込みもブロックしない。
ColumnSegment(列セグメント):
RowSegment のデータが一定量に達すると、バックグラウンドプロセスがそれを圧縮・変換し、列指向フォーマットのディスクセグメントに落とす。この変換プロセスを フラッシュ と呼ぶ。ColumnSegment は差分圧縮やランレングス圧縮を組み合わせた高圧縮率のフォーマットで、大規模スキャンに最適化されている。
重要なのは、この2つのセグメントは 同一のテーブル定義の下に共存する ということだ。OLTPクエリは主にRowSegmentを、OLAPクエリはColumnSegmentを参照する——しかし、これは「2エンジン」ではない。クエリオプティマイザが単一のクエリ実行計画の中でRowSegmentとColumnSegmentを 統合的に 読み取れる設計になっている。
[テーブルへの書き込み]
↓
RowSegment(メモリ上・行指向)
↓ バックグラウンドでフラッシュ
ColumnSegment(ディスク・列指向)
[クエリ実行]
クエリオプティマイザ → RowSegment + ColumnSegment を統合スキャン
4-3.コンパイル型クエリ実行エンジン
SingleStore のもう一つの特徴が、クエリを LLVM*⁴でネイティブコードにコンパイルする実行エンジンだ。
インタプリタ型の実行エンジンは、命令ごとに型チェックやディスパッチが発生するオーバーヘッドがある。コンパイル型では、クエリの構造がわかった段階でそれを C++ に近い中間表現に変換し、最適化されたマシンコードを生成する。これにより、特にOLAPクエリの集計・スキャン性能が大幅に向上する。
さらに注目すべきは、コンパイルと HTAP の組み合わせ効果だ。RowSegment(行形式)と ColumnSegment(列形式)の両方を扱うコードが、クエリ単位で最適化されてコンパイルされる。型キャストや分岐が最小化されるため、2フォーマット混在のペナルティが実用上ほとんど現れない、というのが論文の主張だ。
4-4.クラウドネイティブ対応:ストレージとコンピュートの分離
SIGMOD 2022 の論文タイトルに「Cloud-Native」という言葉が入っていることからもわかるように、SingleStore はクラウド環境での運用を強く意識している。
具体的には、ColumnSegment をオブジェクトストレージ(S3 互換)に保存し、コンピュートノードはステートレスに保つアーキテクチャへの移行が進んでいる。RowSegment はノードのメモリとローカルディスクにキャッシュされ、書き込み直後のデータへの低レイテンシアクセスを保証する。
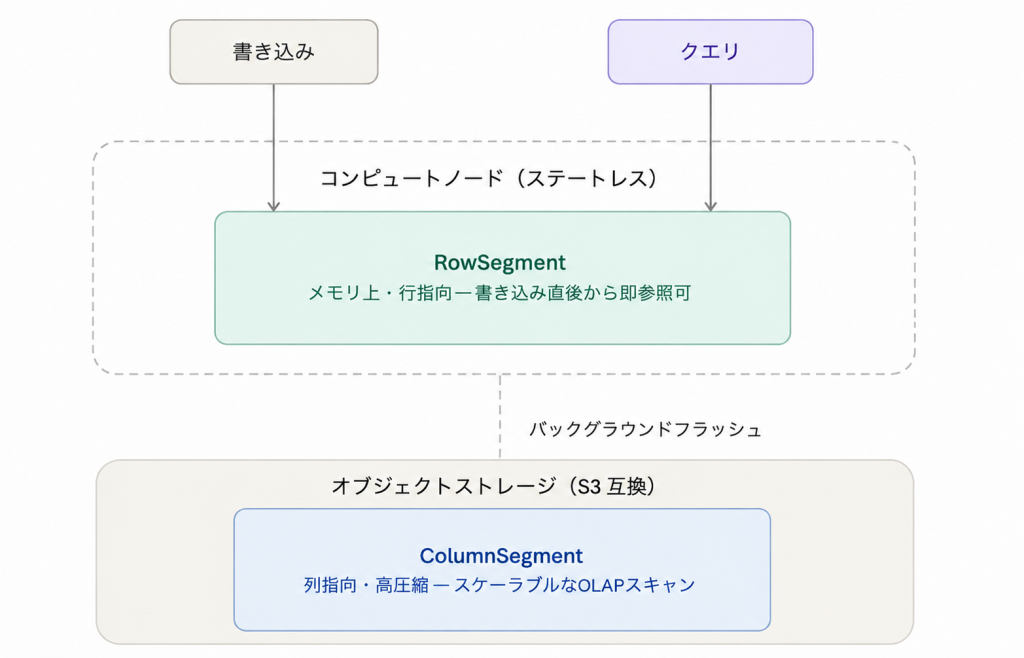
これはSnowflakeのコンピュート・ストレージ分離に近い発想だが、決定的な違いがある。SnowflakeはOLAP専用で設計されたストレージ分離であるのに対し、SingleStoreのそれは OLTPワークロードを犠牲にしない設計 になっている点だ。RowSegmentをメモリに保持することで、書き込み性能と読み取りレイテンシを確保しながら、ColumnSegmentのスケーラビリティの恩恵も受けられる。
5. 論文の検証:本当に「単一アーキテクチャ」か?
5-1.「2エンジン」との違いを問い直す
前編で TiDB を「高速同期付きの OLTP + OLAP 分離アーキテクチャ」と評した。Universal Storage との違いはどこにあるのか。改めて整理したい。
TiDB(TiKV + TiFlash)では:
- 2つの独立したストレージエンジンが別々のプロセスで動く
- Raft プロトコルで行→列の同期が行われる
- トランザクションのコミットとTiFlashへの反映の間に時間差がある
- クエリは「どちらのエンジンを使うか」を最初に決定する
SingleStore(Universal Storage)では:
- RowSegment と ColumnSegment は 同一プロセス内 で管理される
- フラッシュはトランザクション外のバックグラウンド処理だが、未フラッシュデータはRowSegmentとして同一クエリで読める
- コミット後、RowSegmentにある最新データは即座にクエリから参照できる(データ鮮度の問題がない)
- 1つのクエリが RowSegment と ColumnSegment を 統合スキャン できる
この「同一プロセス内での統合」と「クエリをまたいだ完全なデータ鮮度の保証」が、構造上の本質的な差異だと考える。
5-2.ベンチマーク結果の読み方
論文の Section 6 では、HTAP の代表的なベンチマークである CH-benCHmark*⁵を用いた性能評価が行われている(結果は論文 Table 3 に集約されている)。TPC-C のトランザクションワークロード(TW)と TPC-H の分析ワークロード(AW)を同じDBに同時実行し、それぞれのスループットがどう変化するかを測定したものだ。テスト環境は 2 Leaf ノード・16 vCPU、1,000 ウェアハウス、20 分間の実行という条件で統一されている。
論文の Table 3 が示した5つのテストケースを順に見ていく。
| Case | 構成 | OLTP(TpmC) | OLAP(QPS) |
|---|---|---|---|
| 1 | TW 50本のみ(単独上限) | 7,530 | — |
| 2 | AW 2本のみ(単独上限) | — | 0.076 |
| 3 | TW 50本 + AW 2本、同一ワークスペース | 3,950 | 0.039 |
| 4 | TW 50本 + AW 2本、ワークスペース分離(32 vCPU) | 7,454 | 0.062 |
| 5 | Case 4 と同構成、Blob ストレージ無効 | 7,545 | 0.065 |
Case 3(OLTPとOLAPの相互干渉):
同一ワークスペースで混在実行すると、OLTP は 7,530 → 3,950 TpmC(▲47%)、OLAP は0.076 → 0.039 QPS(▲49%)とほぼ対称に低下した(Table 3)。「約 50% ずつ」という数字は、一見すると性能劣化のように見える。しかし注目すべきは劣化の「対称性」だ。OLAP の重いスキャンが OLTP を一方的に圧迫するのではなく、2つのワークロードが CPU リソースをほぼ等分に分け合っている。これは RowSegment(メモリ)と ColumnSegment(ディスク)がアクセスパスを物理的に分離しているためで、バッファプールの競合が起きやすい従来型DBとは振る舞いが異なる。
Case 4(ワークスペース分離の効果):
OLAP 専用の読み取りワークスペースを追加*⁶すると(コンピュートは 32 vCPU に倍増)、OLTP スループットは 7,454 TpmC と Case 1 の単独実行(7,530 TpmC)をほぼ維持したまま、OLAP は 0.062 QPS まで回復した。OLAP 単独(0.076 QPS)比では約 18% 低下にとどまる。この差分は、読み取りワークスペースがプライマリから最新トランザクションをリアルタイム複製するコストによるもので、論文によれば平均レプリケーションラグは 1 ミリ秒未満、かつ常に「ほんの数トランザクション遅れ」の状態に保たれていた(Table 3 の注記)。
Case 5(Blob ストレージの影響):
オブジェクトストレージへの非同期アップロードを無効にした Case 5 では OLTP 7,545 TpmC、OLAP 0.065 QPS と Case 4 との差がほとんどなく、「S3 への非同期書き込みがクエリ性能に与える影響は計測限界以下」であることが確認されている(Table 3)。
TPC-H・TPC-C 単体での競争力(Table 1・2):
CH-benCHmark 以外の結果も補足しておく。OLAP 専用のクラウドデータウェアハウス2社(論文内では CDW1・CDW2 と匿名)との TPC-H(1TB スケール)比較では、S2DB のジオミーン応答時間は 8.57 秒、CDW1 は 10.31 秒、CDW2 は 10.06 秒で、ほぼ同等のクラスタ価格帯において SingleStore がトップだった(Table 2)。OLTP 専用のクラウドデータベース(論文内では CDBと匿名)は同 TPC-H を 24 時間以内に完走できなかった。逆に TPC-C(1,000 ウェアハウス)では SingleStore が 12,556 TpmC で CDB の 12,582 TpmC にほぼ並んでいる(Table 1)。単体ベンチマークで OLTP・OLAP どちらの専用品とも渡り合えるのは、ColumnSegmentの圧縮・スキャン性能とRowSegmentの書き込み性能を単一ストレージで両立しているためだ、というのが論文の主張だ。
ただし、私の経験から言うと、このようなベンチマークは「制御された条件」での数字であり、実際の運用では、スキーマの複雑さ、更新パターンの偏り、フラッシュのタイミング、ColumnSegmentのコールドスタートなど、さまざまな変動要因が絡むので、実際の世界とは差がある。
6.「HTAPの夢」は実現したか——総評
6-1.SingleStore が越えたもの
30年以上この業界にいる立場から言えば、SingleStore の Universal Storage は「これまでと何かが違う」という感覚を持たせる設計だ。技術的な根拠は以下の3点だ。
- 同一プロセス・同一スキャン:
2エンジン構成の製品が持つ「エンジン間の非同期性」「クエリルーティングの境界」がない。これは小さいようで大きな違いで、「同じデータについての問いに、常に最新の答えを返す」という保証につながる。 - コンパイル型実行エンジンとの相乗効果:
行と列の両形式を扱うコストを、コンパイル最適化で吸収できる設計は他に例がないと思う(SAP HANAのような純粋なインメモリ系は除く)。 - クラウドネイティブな分離設計:
RowSegmentをメモリに、ColumnSegmentをオブジェクトストレージに置くことで、OLTPの応答性とOLAPのスケーラビリティを同時に確保しようとしている。これは「現代のクラウド環境でHTAPを実装する」という問いへの、現時点では最も現実的な解の一つだと思う。
6-2.まだ残る課題
一方、正直に言えば「夢の完全実現」とはまだ言えない部分もある。
フラッシュのタイムラグ:
RowSegmentからColumnSegmentへのフラッシュはバックグラウンド処理であり、フラッシュ未完了のデータは列形式での高速スキャンの恩恵を受けられない。大量の書き込みが続く環境では、ColumnSegmentの「鮮度」をどう保つかが運用上の課題になりうる。
マルチテナント・大規模環境での振る舞い:
クラウドネイティブ設計を謳う以上、マルチテナントや数百ノード規模での挙動が気になる。論文ではこの領域の記述が薄い。実際の大規模導入事例が増えてきたときに、設計の限界が見えてくる可能性はある。
コスト構造:
SAP HANAほどではないが、RowSegmentをメモリに保持するコスト構造は、データ量が増えるにつれて問題になりうる。オブジェクトストレージへのオフロードが進んだとしても、「どこまでメモリに置くか」のチューニングは残る。
6-3.それでも、なぜ期待するのか
HTAPという概念が提唱されて10年以上が経った。「なぜまだ実現していないのか」という問いへの私の答えは、「アーキテクチャの根本問題と、現場の運用コストが噛み合っていなかったから」だ。
技術的には正しくても、運用が複雑すぎる(TiDB)。OLAPは速いがOLTPが中途半端(Snowflake UniStore)。性能は出るがコストが現実的でない(SAP HANA)。そういった壁が続いてきた。
SingleStore の Universal Storage が興味深いのは、「アーキテクチャの純度」よりも「現場で使えるか」というバランスを意識しているように読める点だ。クラウドネイティブへの対応、PostgreSQL互換ではなくMySQL互換による移行のしやすさ*⁷、JITコンパイルによる「速さの追求」——これらは研究室の設計ではなく、実際のエンジニアリング判断の積み重ねに見える。
おわり
前編・後編を通じて、HTAPの歴史を30年にわたって追いながら、現代の製品群がどこで詰まり、SingleStore がどのようにその壁に向き合っているかを見てきた。
「DBエンジニアはHTAPの夢を見るか?」——答えは、まだ夢の途中だと思う。しかし、SingleStore の設計を見る限り、その夢は以前よりずっと現実に近づいている。
いずれ、「OLTP用DBとOLAP用DBを別々に立てる」という設計が当たり前ではなくなる日が来るかもしれない。そのとき、今われわれが「当然」と思っている運用コストの多くが、静かに消えているはずだ。
それが実現するかどうかを、引き続き現役の目で見ていきたい。
なお、今回は分量の都合で触れなかったが、SingleStoreは高速なベクトル検索機能も持っており、AIシステムのバックエンドとしてもとても有望である。VLDB*⁸に論文*⁹があるようなので、今後の AIとDBの関係のネタのときにでも取り上げるかもしれない。
脚注・参考
*¹SIGMOD(Special Interest Group on Management of Data): 世界最大の計算機学会であるACMが設置している、データ管理に関する特別興味グループの略称。ここは理論と実用が高度に融合する場であり、現在表舞台で活躍している様々なRDBMSの論理的支柱をなす論文がいくつか存在しているので、興味のある人は是非探してみてほしい。以下にいくつかタイトルを紹介する。
-The Snowflake Elastic Data Warehouse (SIGMOD 2016)
-Spanner: Becoming a SQL System (SIGMOD 2017)
-Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (SIGMOD 2017)
-TiDB: a Raft-based HTAP database (SIGMOD 2020)
*²Cloud-Native Transactions and Analytics in SingleStore(https://dl.acm.org/doi/epdf/10.1145/3514221.3526055)
著者はSingleStoreのエンジニアリングチームによるもの。SIGMOD 2022に採択されており、実装の詳細まで踏み込んだ論文である。
*³MVCC(Multi-Version Concurrency Control): 複数バージョン同時実行制御。書き込みと読み取りを互いにブロックしないために、データの旧バージョンを保持しておく仕組み。Oracle、PostgreSQL、MySQL(InnoDB)など主要なRDBMSが採用している。「読み取りは書き込みをブロックせず、書き込みは読み取りをブロックしない」がMVCCの基本思想。
*⁴LLVM:コンパイラ作成のための基盤となるオープンソースプロジェクト。名称は「Low Level Virtual Machine」の略だが、現在は仮想マシン技術の枠を超えプロジェクト全体の名称となっている。Clang(C/C++コンパイラ)の基盤として広く普及しているほか、実行時に効率的な機械語を生成できる特性から、DBMSのクエリコンパイルへの採用も進んでいる。SingleStoreのほか、HyPerやDuckDBなど、現代の高性能DBMSの多くがLLVMを活用している。
*⁵CH-benCHmark: TPC-C(OLTP)とTPC-H(OLAP)を組み合わせたHTAP専用のベンチマーク。「同じDBに対してOLTPとOLAPを同時実行したとき、それぞれの性能がどう変化するか」を測定することを目的に設計されている。
*⁶ワークスペースの追加: SingleStoreでのワークスペースの追加は、Snowflakeでいうところの仮想ウェアハウスの追加と同義である。例えば ETL/ELT用と BI/分析用などの異なるワークロードを分離して無駄なリソース競合を回避させる用途でワークスペースや仮想ウェアハウスを追加する。
*⁷MySQLとの互換性について: SingleStoreはMySQL互換のプロトコルを持つため、MySQLドライバやORMをそのまま使えることが多い。PostgreSQL互換のAlloyDBやYugabyteDBとは異なるエコシステム選択となる。
*⁸VLDB(Very Large Database): SIGMODと並ぶデータベースとその関連分野における世界最高峰の学術団体および国際会議。
*⁹SingleStore-V: An Integrated Vector Database System in SingleStore(https://www.vldb.org/pvldb/vol17/p3772-chen.pdf)


