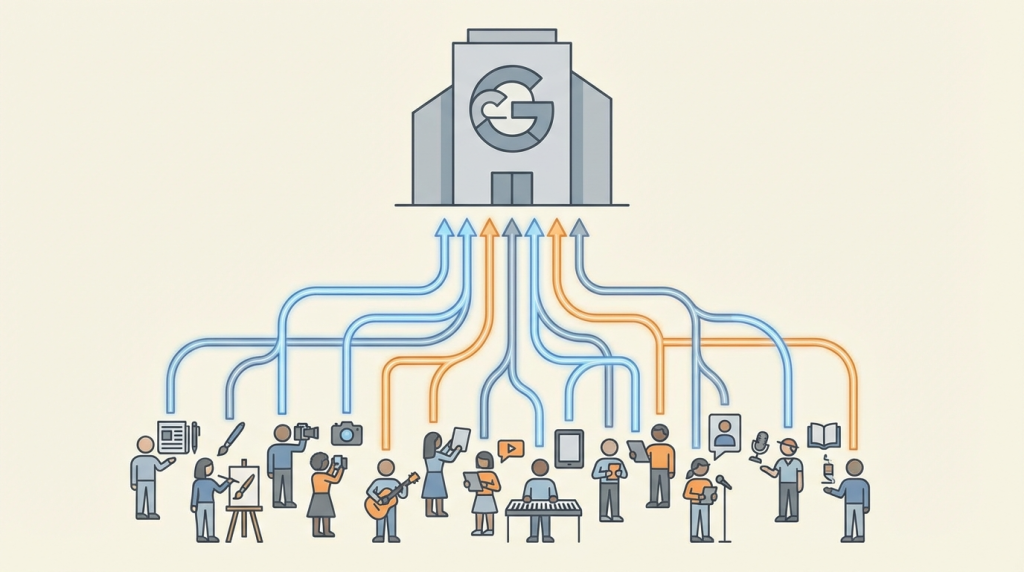
前回のブログで、生成AIが元にしている楽曲データの権利について書きました。
今回も似たネタとなりますが、欧州連合(EU)がグーグルのAI学習データの利用について問題視し、調査を開始したという記事が出ました。
グーグルに限らず、AIモデルの学習におけるオンラインコンテンツ(報道機関やクリエーターの著作物)が適正な対価なく利用されていることが、独占禁止法に抵触しているのではないかということのようです。
一方で、グーグルは、買収し傘下にあるYouTubeの動画を、競合他社がAIの学習に使用することを規約で禁止しています。この点は、グーグル本体のAIを強化し、競合他社を排除する「支配的地位の乱用」と思えますし、確かにアンバランスな対応に見えます。
グーグルが言うように、AI学習にコンテンツを提供してもらうことでパブリッシャーに送客しているという見方もありますが、実際には、生成された答えで完結してしまい、提供元のサイトへの顧客の流入が減少したり、ゼロクリックになってしまうことがあるのも事実です。
このバランスは非常に難しいところですが、AIの学習と著作権の問題は、現在のところ収束する着地点が見えていません。
しかし個人的には、前回のブログでも書いたように、コンテンツを生み出している著作権者に対して充分な対価を支払うことが優先されるべきだと思います。コンテンツがなければAIは成り立ちませんが、コンテンツは単独でも成立します。
グーグルに限らず、AIサービス提供者とコンテンツ提供者の共存共栄を考えなければ、AIの未来は危ういものになるでしょう。
我々は、このような新たな技術革新から大きな恩恵を受けていますが、その一方で搾取される人もいます。
これからさらにAIを活用していくためには、グーグルなどのAI提供者が積極的に解決に向けて協力していくことを期待します。