Qlik データ統合

マルチデータベース間の
リアルタイムデータ統合プラットフォーム
リアルタイムデータ統合プラットフォーム
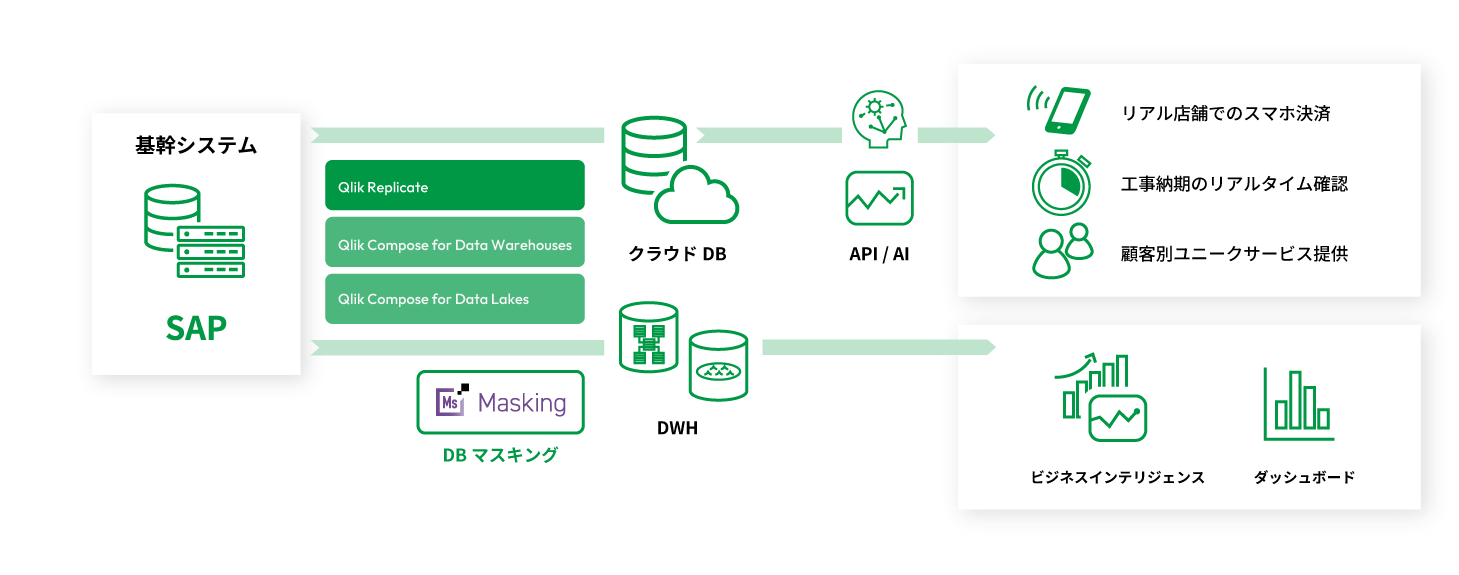
バッチ処理の呪縛からデータベースを解放。データベース間のリアルタイム・レプリケーションをエージェントレス・低負荷で実現する。データウェアハウス・データレイクのプロセスを自動化してスクリプティングやコーディングを不要に。導入から成果を生み出すまでの時間を短縮するデータ統合のベストプラクティクス。
クラウドベースのソリューションはこちら
Qlik Talend Cloud®SAPテストデータ管理ソリューションはこちら
Qlik Gold Client®
マルチデータベース、マルチクラウド間をリアルタイムデータ同期。
既存システムに負荷をかけずに、
迅速で安全なデータ統合/移行を実現するDXソリューション。
既存システムに負荷をかけずに、
迅速で安全なデータ統合/移行を実現するDXソリューション。
Qlikデータ統合の特徴
01 構築も変更も迅速、リアルタイム性を追求
Qlikデータ統合は、ビックデータを持つエンタープライズDXに必須なリアルタイム性と拡張性を同時に提供します。Qlik Replicateはリアルタイムレプリケーションの自動構築を、Qlik Compose for Data Warehousesはデータマートの設計、実装、更新の自動化による迅速な構築と変更を、 Qlik Compose for Data Lakesはデータパイプラインを最速で作成。取り込んだ各データのメタデータを管理することで、分析への最短ルートを達成します。
POINT 1
データベースへ負荷をかけずに最新データを連携
エージェントレスで限りなく低負荷での運用が可能
POINT 2
迅速に連携対象データを追加・変更
高性能な独自CDC技術により、データ連携のリアルタイム性を向上
POINT 3
主要なデータベースをすべて網羅
異種間を含む様々な組み合わせに対応
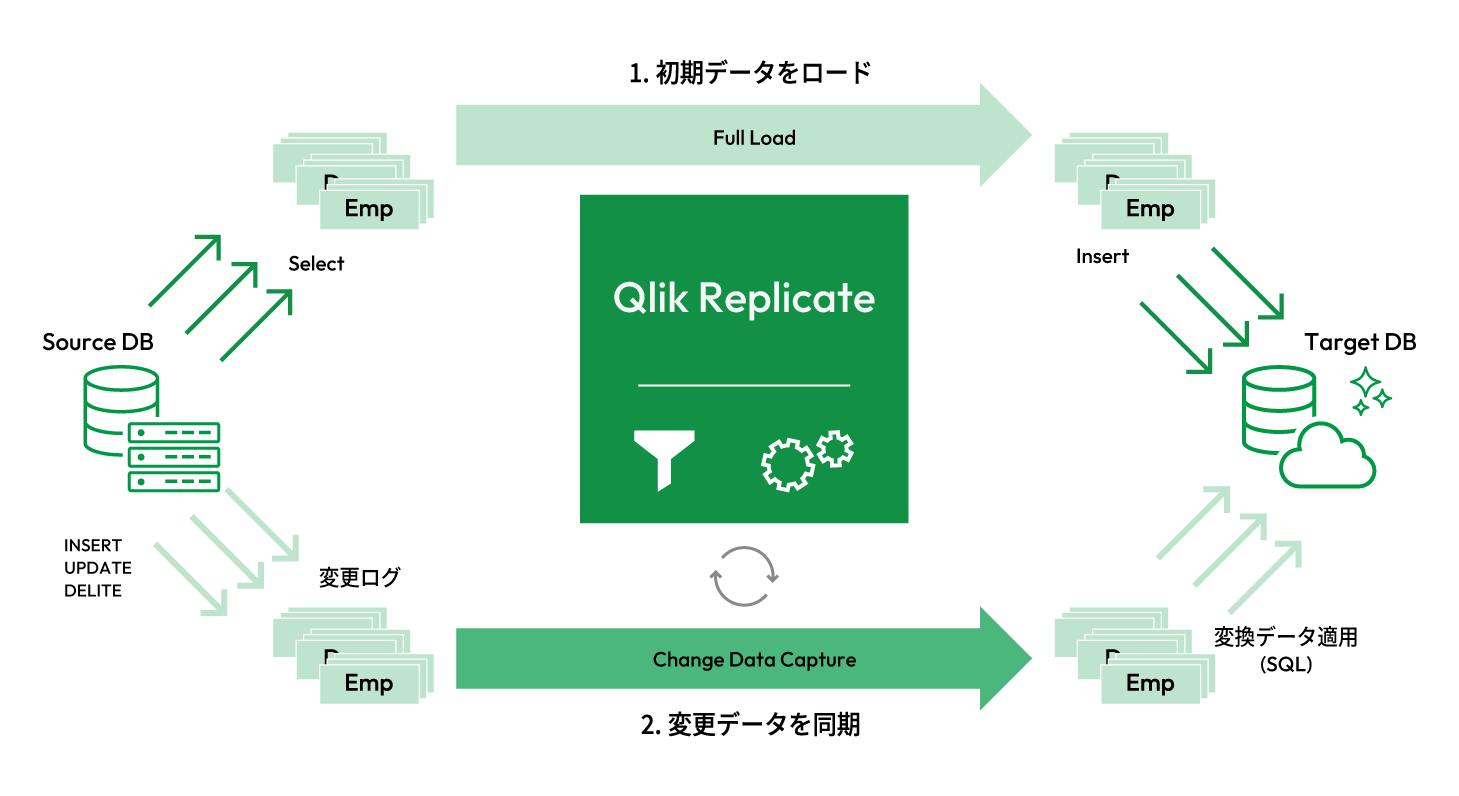
02 Qlik Replicate
Qlik Replicateは異種データベースだけでなく、メインフレーム、SAP、Salesforceなどのデータを分析基盤などへリアルタイムに連携するレプリケーションソフトウェアです。多様化するデータ活用基盤の再構築において、既存システムに負荷をかけずに迅速で安全なデータ統合/移行が達成できます。ソースデータベースからターゲットデータベースへデータをコピーするのではなく、変更データログを読み込んで反映することで、限りなくリアルタイムに近いデータ連携を実現します。
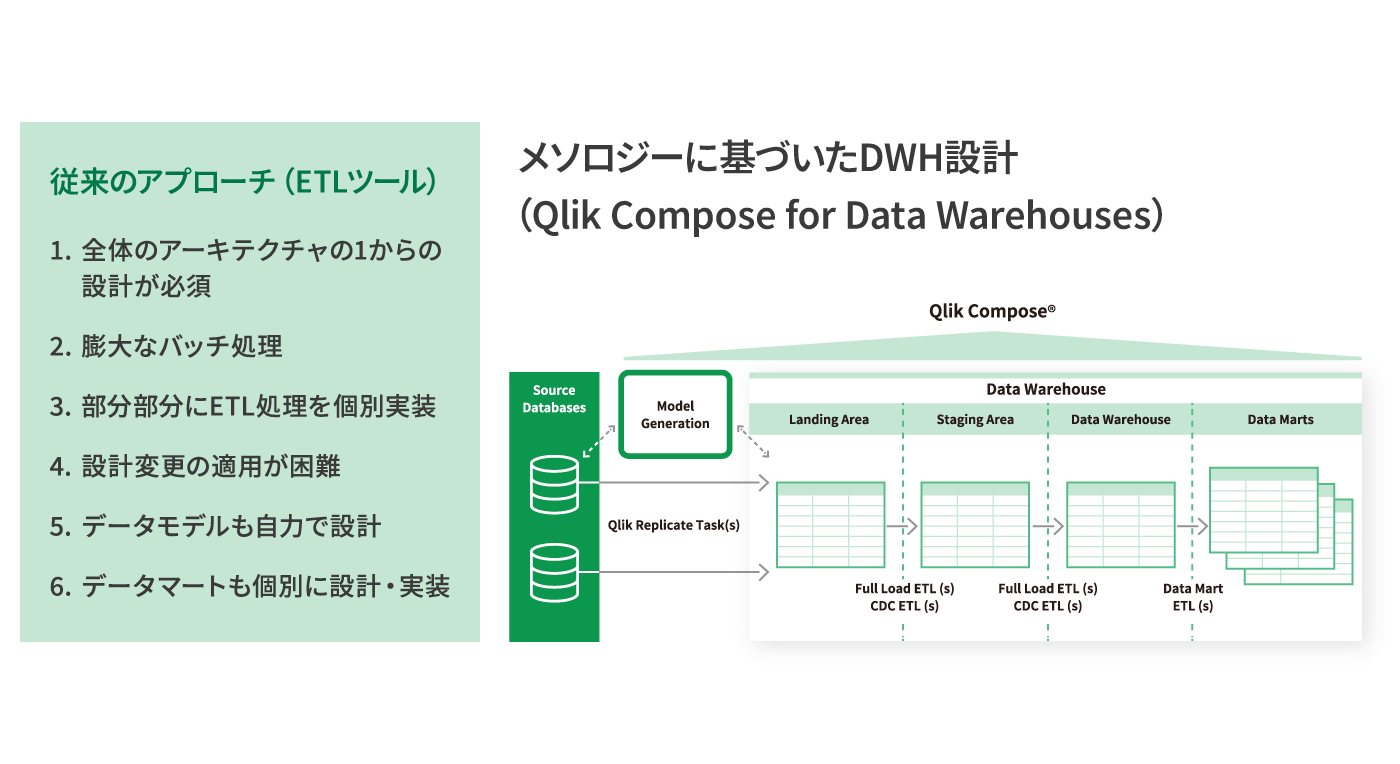
03 Qlik Compose for Data Warehouses
Qlik Compose for Data Warehousesはリアルタイムデータウェアハウスを実現するためにデータマートの設計、実装、更新を自動化します。その特徴は、汎用的なETLツールとは決定的に異なるアプローチにあります。設計からコード生成、更新の適用まで、ベストプラクティスと実績のある設計パターンによって簡便化・自動化を実現。データウェアハウスの構築・管理をスピーディーなものに変えます。
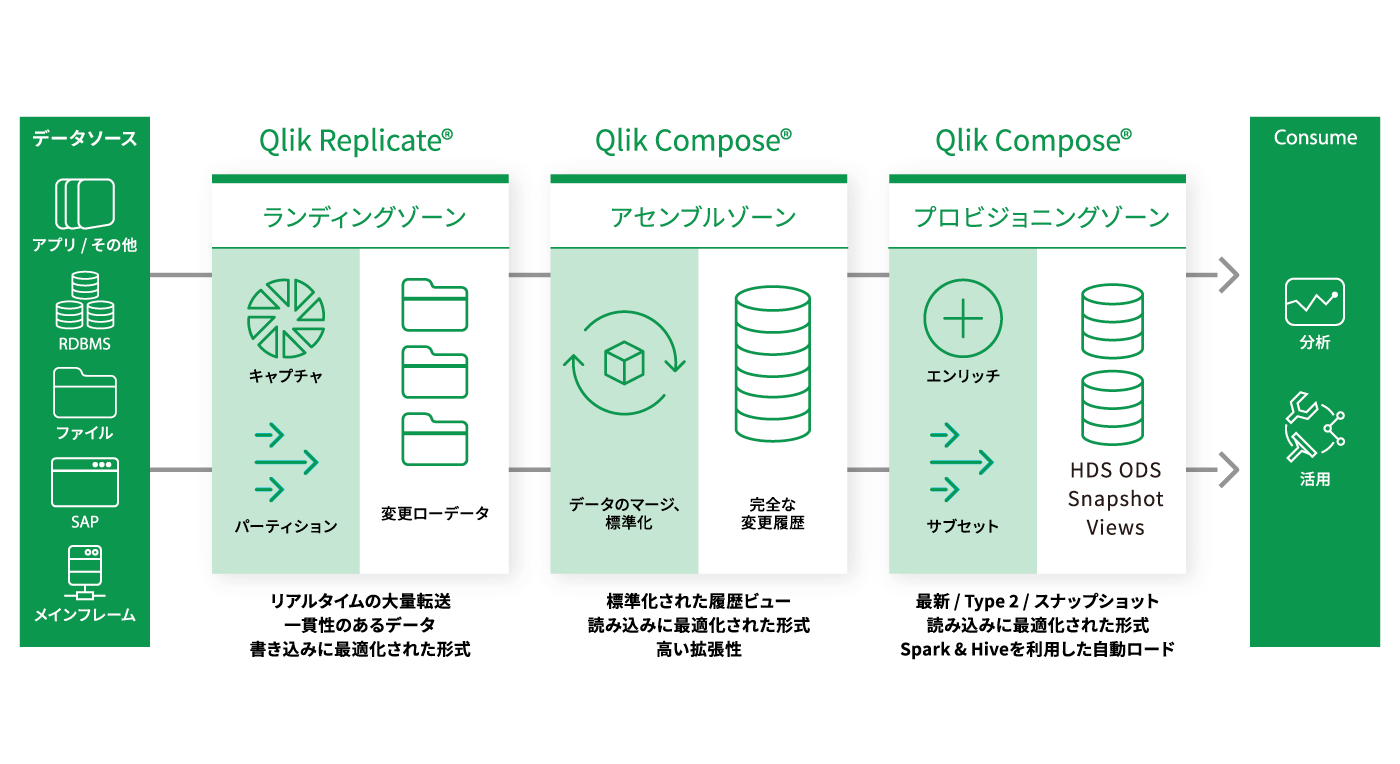
04 Qlik Compose for Data Lakes
データレイクは様々な非構造化データをスキーマで事前定義することなく取り込める優位性がある反面、取り込んだデータの管理に困難が伴います。Qlik Compose for Data Lakesは各データのメタデータを自動収集してカタログ化し、必要な時に最適なデータを取り出すことを可能にします。複雑なコーディングを排除して自動化することで、関連するリスク・コストを削減。データレイクの導入から成果を生み出すまでの時間を短縮します。
Qlikデータ統合の機能
FUNCTION 01 Qlik Replicateによるレプリケーション
①テーブル全体の高速レプリケーション
Qlik Replicateはデータベーステーブル全体を高速にレプリケーション。更新時も変更データログを読み込む独自CDC(Change Data
Capture、変更データキャプチャ)技術を利用して差分のみをレプリケートします。ソース、ターゲット共にデータベースを停止する必要はありません。
②主要なデータベースを網羅
ソースとなるデータベースやターゲットに指定するデータベースは、クラウド/オンプレミスのどちらかだけでなく、ハイブリッド環境も選択可能です。
ソース
 Database
Database
|
Oracle、 SQL Server、 DB2 iSeries、 DB2 z/OS、 DB2 LUW、 MySQL、 PostrgeSQL、 Sybase ASE、 Informix、 SAP HANA、 ODBC |
 Mainframe
Mainframe
|
DB2 z/OS、 IMS/DB、 VSAM、 COBOL Copybooks |
|---|---|---|---|
 SAP
SAP
|
ECC、 ERP、 CRM、 SRM、 GTS、 MDG、 SAP ECC - HANA、 SAP HANA (database) |
 EDW
EDW
|
Exadata、 Teradata、 Netezza、 Vertica、 Pivotal |
 Cloud
Cloud
|
Amazon RDS (SQL Server, Oracle, MySQL, Postgres)、 Amazon Aurora (MySQL)、Amazon Redshift、 Azure SQL Server MI、 Google Cloud SQL (MySQL, PostgreSQL) |
 SaaS
SaaS
|
Salesforce |
 Flat Files
Flat Files
|
XML、 JSON、 Delimited |
ターゲット
 AWS
AWS
|
RDS (MySQL, Postgres, MariaDB, Oracle, SQL Server)、 Aurora (MySQL, Postgres)、 S3、 EMR、 Kinesis、 Redshift、 Snowflake、 Databricks (Q2) |
 Azure
Azure
|
DBaaS (SQL DB)、 DBaaS (MySQL, Postgres)、 ADLS Gen1 & 2、 BLOB、 HDInsight、 Event Hub、 Synapse (SQL DW)、 Snowflake、 Databricks |
|---|---|---|---|
 Google
Google
|
Cloud SQL (MySQL, Postgres)、 Cloud Storage、 Dataproc、 Pub/Sub (‘20)、 BigQuery (‘20)、 Snowflake (‘20) |
 Data Lake
Data Lake
|
Hortonworks、 Cloudera、 MapR、 Amazon EMR、 Azure HDInsight、 Google Dataproc |
 EDW
EDW
|
Exadata、 Teradata、 Netezza、 Vertica、 Sybase IQ、 SAP HANA、 Microsoft PDW |
 Database
Database
|
Oracle、 SQL Server、 DB2 LUW、 MySQL、 PostgreSQL、 Sybase ASE、 Informix、 MemSQL |
 Streaming
Streaming
|
Kafka、 Amazon Kinesis、 Azure Event Hubs、 MapR Streams |
 SAP
SAP
|
SAP HANA (database) |
 Flat Files
Flat Files
|
Delimited(e.g., CSV, TSV) |
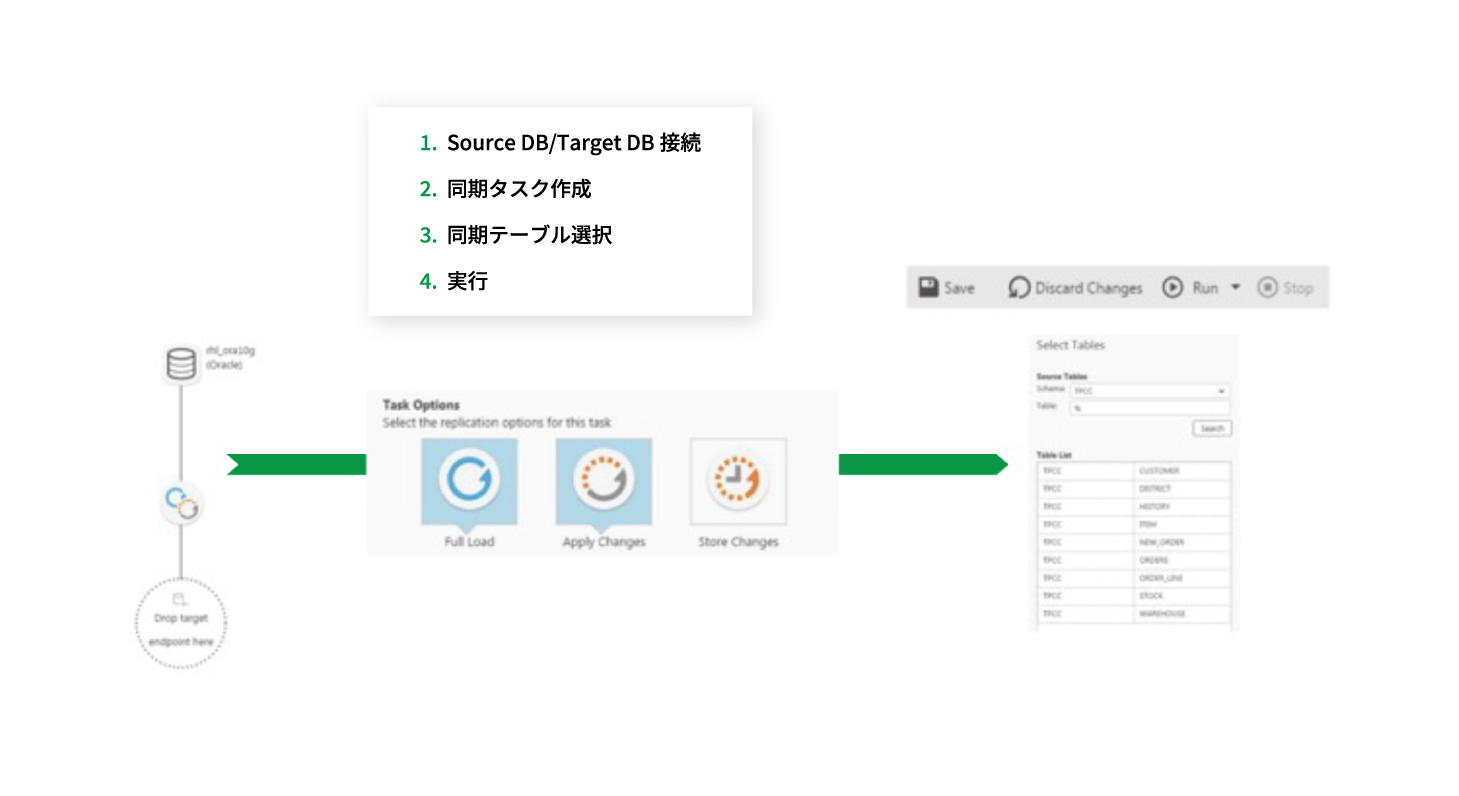
③WebベースのUI
レプリケーションタスクのモニタリングを可能にする直観的なUIはブラウザベースで提供されます。「1クリックレプリケーション」のデザインにより、データベーススキーマ、テーブル全体(スナップショットレプリケーション)、変更差分(トランザクションレプリケーション)の手順は自動化されるため、クリックするだけで多くの操作が完結。エージェントをソース、ターゲットのいずれのデータベースにもインストールする必要はありません。
④Qlik Replicateサーバのシステム要件
| 推奨ハードウェアスペック | 対応OS(64bit) |
|---|---|
|
CPU:8core以上 Memory:8GB〜64GB Disk:320GB〜500GB NW:1Gbps〜10Gbps×2 |
Windows Server 2012 R2 Windows Server 2016 Windows Server 2019 Windows Server 2022 Red Hat Enterprise Linux 7.X, 8.X |
FUNCTION 02 Qlik Compose for Data Warehouses
①データウェアハウスオートメーション機能
- データモデル/データウェアハウスの設計、開発、保守、文書化を自動化
- テーブルの作成、インスタンス生成、マッピングを自動化
- データマートを迅速に作成
- データを継続的にリアルタイムでデータウェアハウス/データマートに複製
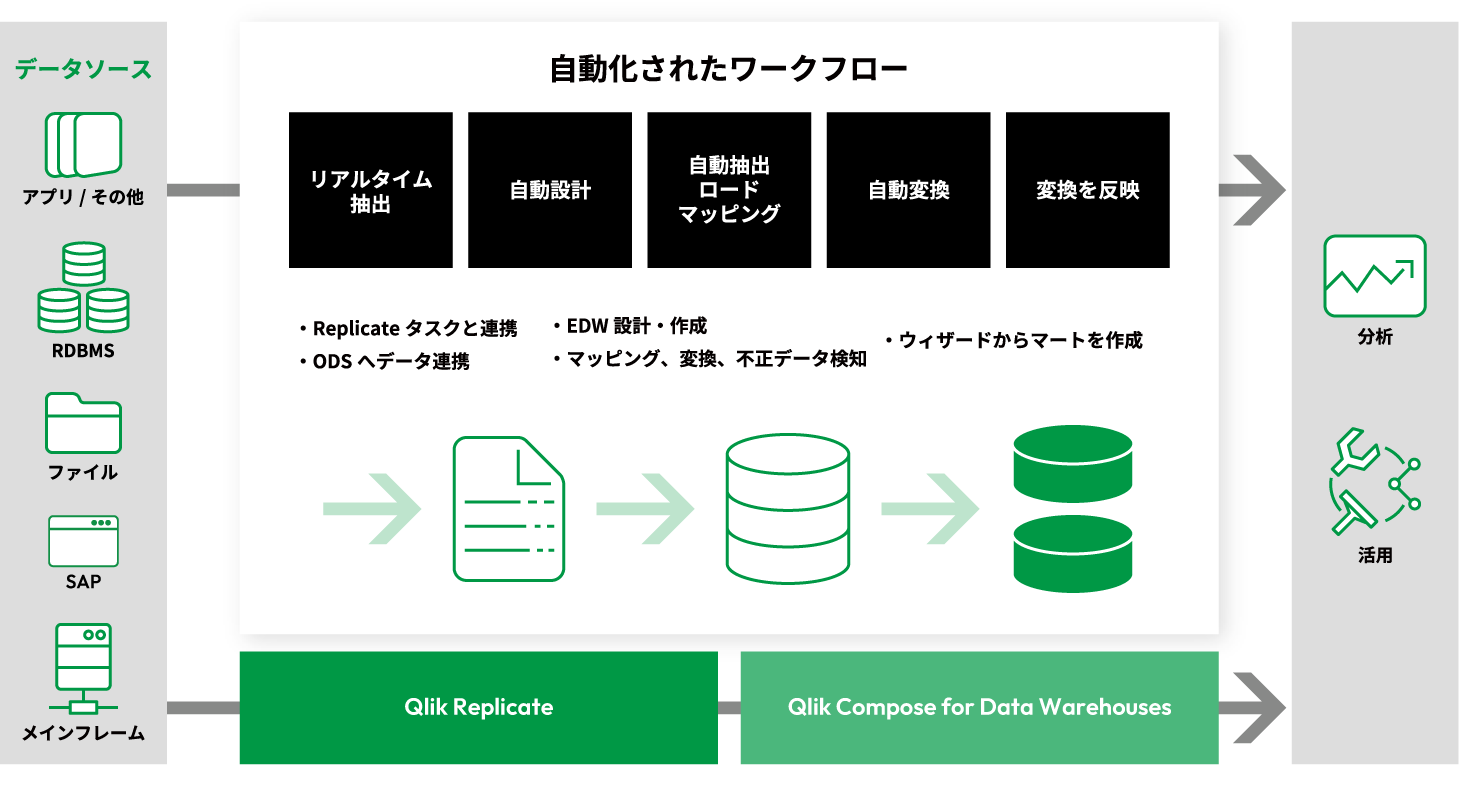
②Qlik Compose for Data Warehousesの対応環境
|
Database
|
Oracle、 SQL Server、 DB2 iSeries、 DB2 z/OS、 DB2 LUW、 MySQL、 PostrgeSQL、 Sybase ASE、 Informix、 SAP HANA、 ODBC |
Mainframe
|
DB2 z/OS、 IMS/DB、 VSAM、 COBOL Copybooks |
|---|---|---|---|
|
SAP
|
ECC、 ERP、 CRM、 SRM、 GTS、 MDG、 SAP ECC - HANA、 SAP HANA (database) |
EDW
|
Exadata、 Teradata、 Netezza、 Vertica、 Pivotal |
|
Cloud
|
Amazon RDS (SQL Server, Oracle, MySQL, Postgres)、 Amazon Aurora (MySQL)、Amazon Redshift、 Azure SQL Server MI、 Google Cloud SQL (MySQL, PostgreSQL) |
SaaS
|
Salesforce |
|
Flat Files
|
XML、 JSON、 Delimited |
※Qlik Replicateでサポートされているデータソースはすべて、Qlik Composeのデータソースとして使用できます。
※Qlik Replicateのデータソースを使用する場合は、ランディングポイント上で検出を行う必要があります。
ターゲットとしてサポートされているデータウェアハウス
| Data Warehouses | Version |
|---|---|
| Microsoft SQL Server | 2012, 2014, 2016, 2017 |
| Microsoft Azure SQL Database (Microsoft SQL Server データベース接続設定を経由) |
N/A |
| Oracle ※すべてのOracleエディションに対応 |
11.x, 12.x, and 18.3 |
| Amazon Redshift | Amazon Redshift |
| Microsoft Azure SQL Server Data Warehouse | N/A |
| Snowflake | N/A |
③Qlik Compose for Data Warehousesのシステム要件
サポートされているプラットフォームとデータベースのバージョン
| インストール可能なWindowsプラットフォーム | サポートされているブラウザ |
|---|---|
|
Windows Server 2012(64-bit) Windows Server 2012 R2(64-bit) Windows Server 2016(64-bit) Windows Server 2019(64-bit) |
Internet Explorer 11 Chrome(最新バージョン) Firefox(最新バージョン) |
FUNCTION 03 Qlik Compose for Data Lakes
①データレイクオートメーション機能
- テーブル作成を自動化、データ構造を整理して系統を追跡、管理されたデータレイクを実現
- データのインスタンスを生成、ソースとターゲットをマッピング、同期した状態にスキーマを維持
- SparkとHiveを利用した自動ロード
- データを継続的にリアルタイムで管理されたデータレイクに複製
②Qlik Compose for Data Lakesの対応環境/システム要件
サポートされているプラットフォーム、データベースのバージョンおよびデータソースはQlik Compose for Data Warehousesと共通です。
サポートされているHiveディストリビューション
| Hive Distribution | Version |
|---|---|
| HortonWorks |
3.1.x – Apache
Sparkプロジェクトタイプの場合、HortonWorksクラスタはSparkメタデータストアをHiveメタデータストアに設定する必要があります。 2.6.x – フルサポート。 2.5.x – Apache Hive プロジェクトタイプかつ履歴データストアを使用している場合のみサポートされます。 |
| Amazon EMR | 5.15 – 5.23 |
| Cloudera | 5.11 – Apache Hive プロジェクトタイプかつ履歴データストアを使用している場合のみサポートされます。 6.1 – HiveとSparkでサポートされています。 |
| Microsoft Azure HDInsight | 3.6 |
| Google Dataproc | 1.2と1.3 はDebianのみ |
| Google BigQuery | プロビジョニングタスクのみに対応 |
| Databricks | 5.3 |
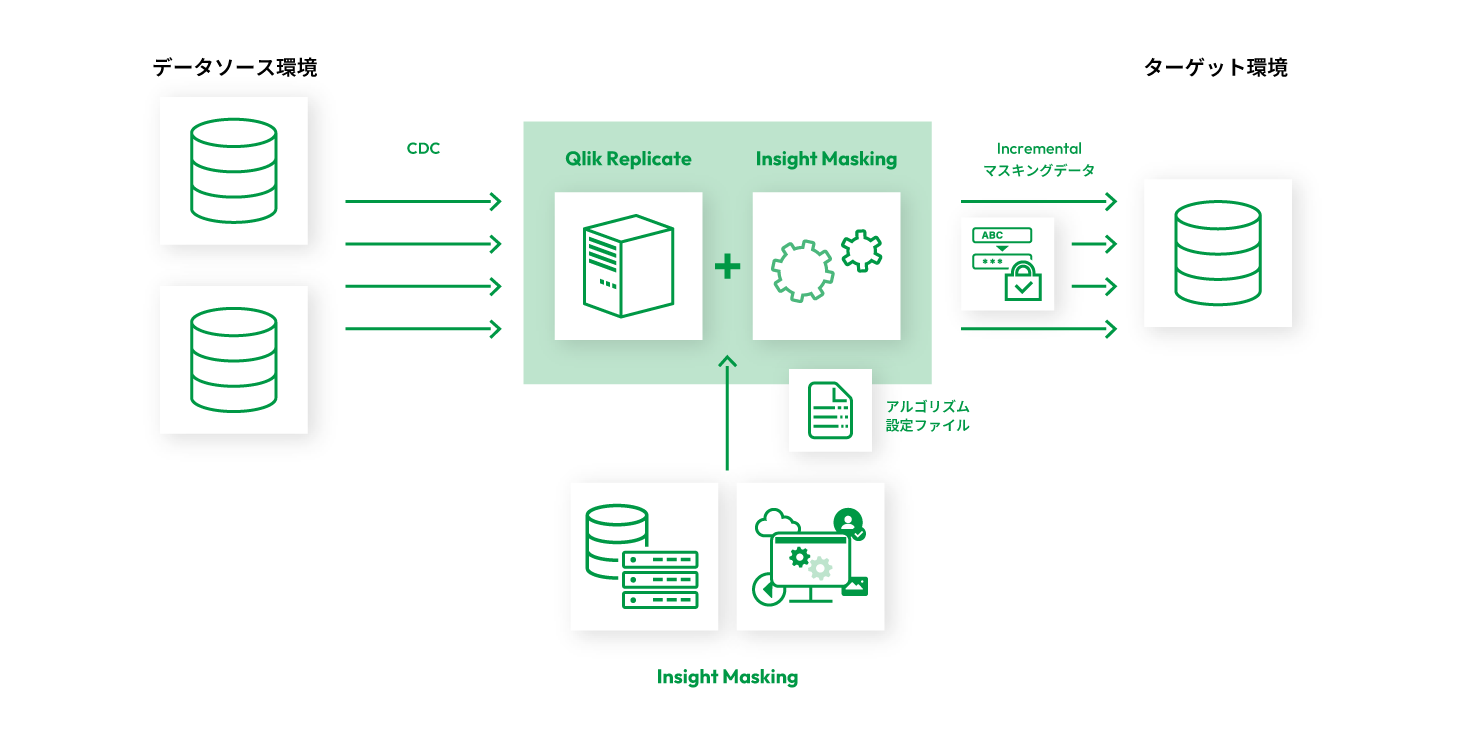
FUNCTION 04 マスキングオプション:Qlik Replicate + Insight Masking
Qlik ReplicateとInsight Maskingを組み合わせることで、レプリケーションデータをリアルタイムにマスキングするオプション機能が利用可能です。
Insight
Maskingが機密情報を日本語に最適化されたAIで自動抽出し、個人情報や機密情報の匿名化を高速実行。データをレプリケーションすると同時にマスキングすることで、マーケティングのデータ活用環境やデータを保護した上での開発環境・検証環境の利用を実現します。マスキングされたデータには参照整合性、カーディナリティが維持され、「使えるデータ」として利用することができます。
Qlikデータ統合が
解決する課題
theme
01
サービス要件の頻繁な変更に対応する
データ提供依頼の増加に伴い、バッチ処理負荷が増えたりバッチスケジュール枠が逼迫するなど、システム安定稼働へ影響が発生しています。また、データ項目の追加・変更の要求頻度が多くなると、バッチプログラム改修コストが増加します。このようなデータ連携対象システムの追加/回収の依頼にかかる費用や時間の問題を解決します。
theme
02
ビックデータをリアルタイム・セルフサービスで分析する
Qlikデータ統合は主要なデータベースをすべて網羅するだけでなく、エージェントレスであるため限りなく低負荷での運用が可能です。基幹システムデータや外部データをリアルタイムで情報系システムに同期、正確なデータで信頼できるDWHを実装します。さらにInsight Data Maskingとの組込オプションでは、生データに近いビックデータの運用や個人情報の匿名化においても拡張性の高いソリューションを提供します。
theme
03
投資から期待収益を得ることが難しいデータレイクの課題を解決する
スケーラビリティの欠如やソースデータを迅速かつ容易に得られないデータレイクの課題は、Qlikの全自動、高性能、スケーラブル、汎用的なデータ統合ソリューションが解決します。
Qlik Replicate利用シーン
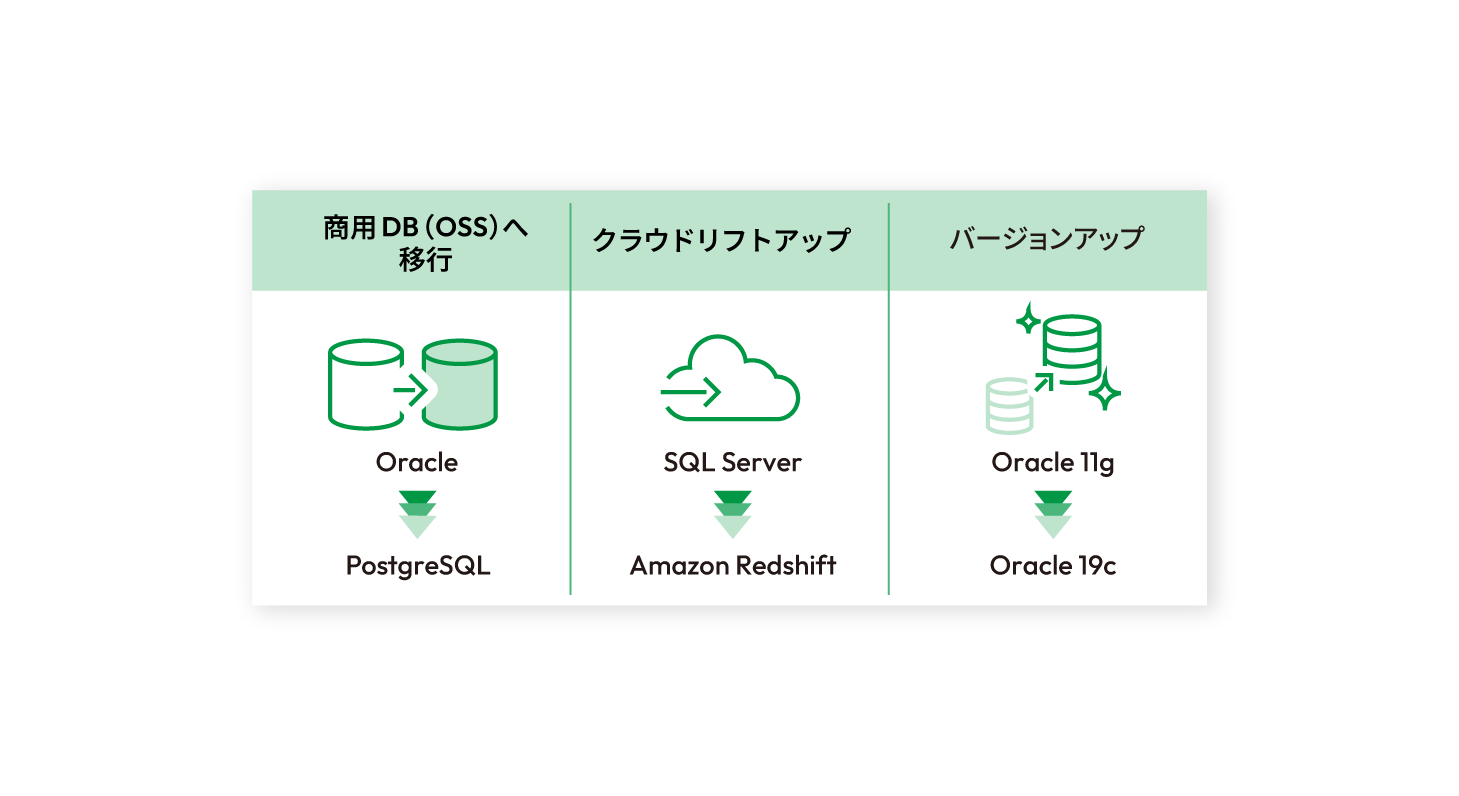
データベース移行
異種データベースの移行、データベースバージョンアップのための移行など、停止時間を最小化にしデータベースを移行
- リアルタイム性の高いデータの転送要件に対応し、ダウンタイムを最小化したデータベース移行
- 異種データベース間であっても、直観的なGUIで簡単なデータ移行を可能に

レプリケーション/データ統合
分析用データ基盤の構築、分散したデータベースを1つのプラットフォームに集約するなど、リアルタイムのデータレプリケーションを実現
- 本番稼働しているメインシステムに負荷をかけずにリアルタイムな分析用環境を構築
- 海外を含む複数の拠点のデータをリアルタイムに同期/集約
- メインフレームから外部にデータを連携
導入事例

DIC株式会社
DICは、デジタル基盤とビジネスプロセスの整備を目的に、SAP ECCからSAP S/4HANAへ移行する際に、周辺システムのデータを統合するデータ活用基盤「デジタル統合プラットフォーム」を新たに構築した。これらを成功させるため、DICはSAPとの連携に優れ、大量データを柔軟かつ効率的に処理できる「Qlik Replicate」を採用した。

株式会社千趣会
千趣会は、それまで利用していたオンプレミス環境をすべてAWSに移行する「脱ホスト」プロジェクトで、データインテグレーションツールとして導入したのは「Qlik Replicate」だった。

Jaguar Land Rover
複雑で時間のかかるデータアクセス 2020 年、Jaguar Land Rover 社は 425,974 台の車両を 127 ヶ国で販売し、大きな成功を収めましたが、それでもなお、多くの組織が現在直面している課題を効果的 […]