「社内に大量の規程・マニュアル・FAQが眠っているけれど、必要な情報を探すのに時間がかかる」「ChatGPTやClaudeに自社のことを答えさせたいが、汎用AIだと正しい答えが返ってこない」——生成AIが業務に浸透し始めた今、こうした次の壁にぶつかる企業が増えています。
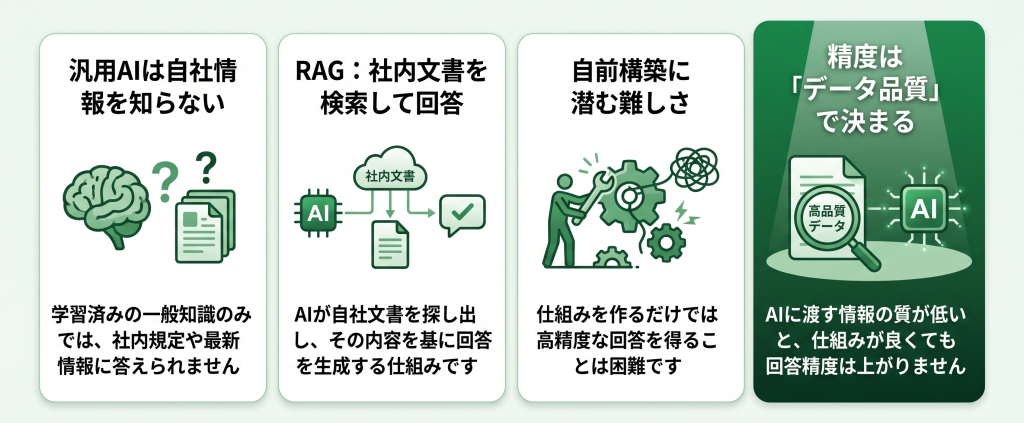
汎用的な生成AIは、学習済みの一般知識には強い一方、自社固有の文書や最新情報は持っていません。そこで注目されているのが、社内文書を検索してその情報をもとにAIが回答する仕組み——RAG(Retrieval-Augmented Generation/検索拡張生成)です。
ただし、RAGを導入すれば自動的に高精度な回答が得られるわけではありません。AIに渡すデータの品質が低いままだと、どれだけ仕組みを作り込んでも精度は上がらない、という落とし穴があります。本記事では、RAGの仕組みと社内活用のメリット、自前構築の難しさ、そしてRAGの精度を本当に決める「データ品質」という前提までを解説します。
この記事で分かること
- RAG(検索拡張生成)の仕組みと、社内データ活用におけるメリット
- 自前でRAGを構築する場合の難しさと、よくある落とし穴
- RAGの精度を本当に左右する「データ品質」という前提
1. なぜ汎用AIは社内のことを正しく答えられないのか
ChatGPTやClaudeなどの汎用的な生成AIは、便利な反面、業務で使おうとすると物足りなさを感じる場面が出てきます。理由は大きく2つあります。
社内固有・最新の情報を知らない
汎用LLMが学習しているのは、インターネット上の公開情報を中心とした一般知識です。自社の規程、マニュアル、FAQ、過去の会議資料、製品仕様書といった社内固有の情報は持っていません。さらに、学習データには時点の制約があるため、最新の改訂版や新製品情報も反映されません。
「社内規程に照らして判断してほしい」「最新の製品仕様に基づいて回答してほしい」と指示しても、汎用AIはそのデータを持っていないため、一般論しか返せないのが現状です。
「それっぽいが間違った回答」への不安
さらに厄介なのは、汎用AIが「知らないことを知らない」と素直に答えるとは限らない点です。情報が不足している領域でも、もっともらしい文章を生成してしまうため、結果として「それっぽいが事実と異なる回答」——いわゆるハルシネーションが発生します。
業務でAIの回答を使うには、どの情報源に基づいた答えなのかを検証できる仕組みが必要です。出典が示されない回答は、たとえ正しく見えても、業務判断の根拠としては使いにくいのが実情です。
ハルシネーションをはじめとする生成AIのリスクと、企業がどう向き合うべきかについては、弊社CEOによる解説記事「ハルシネーションだけじゃない!?最新AIのリスクから感じたこと」もあわせてお読みください。
2. RAGとは?社内データで回答を補強する仕組み
RAG(Retrieval-Augmented Generation/検索拡張生成)とは、AIが回答を生成する前に、関連する社内文書や情報源を検索し、その内容をもとに回答を作る仕組みです。汎用LLMの「知らない問題」と「出典が分からない問題」を、両方ともデータ側から解決するアプローチといえます。
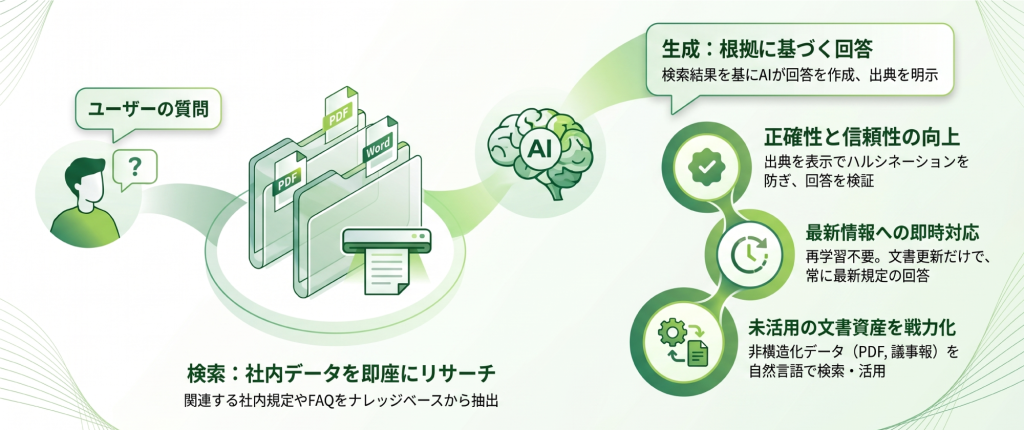
RAGの基本的な仕組み
RAGの動作は、おおまかに次のような流れです。
①ユーザーがAIに質問する(例:「育児休業の取得条件を教えて」)
②AIが社内のナレッジベースを検索する(人事規程、FAQ、過去の通達などから、質問に関連する文書を取り出す)
③検索で得た情報をもとにAIが回答を生成する(汎用知識ではなく、社内の最新情報に基づいた答えを返す)
④回答に出典を添える(どの文書のどの箇所を参照したかを示す)
この仕組みの肝は、AIが「学習で身につけた知識」だけで答えるのではなく、「検索した社内データ」を根拠に答える点にあります。
RAGで実現できること
RAGを社内活用すると、次のようなことが可能になります。
- 社内文書を自然言語で検索・要約:PDF・Word・PowerPointなどの非構造化データをナレッジベースに取り込めば、自然な言葉で質問してAIに要約・回答してもらえます。「規程の何ページを読めばいいか」を覚えていなくても、必要な情報にたどり着けます。
- 出典つきで回答の根拠を検証:AIが参照した文書を出典として提示できるため、回答の正しさを検証できます。「ハルシネーションかもしれない」という不安が大幅に減ります。
- 最新情報への追随:学習し直す必要なく、ナレッジベースの文書を入れ替えるだけで、最新の規程や製品情報に基づいた回答を返せるようになります。
RAGが扱う「非構造化データ」の重要性
企業が持つデータのうち、規程・マニュアル・議事録・契約書・提案書といった文書データは、いわゆる「非構造化データ」と呼ばれます。データベースに整然と格納された構造化データと違って、自由形式の文章なので、これまで検索・分析が難しい領域でした。
RAGは、この非構造化データを社内のAI活用基盤に組み込める仕組みです。社内に眠っていた膨大な文書資産を、AIアシスタント経由で活用できるようになる——ここがRAGの大きな価値です。
3. 通常の対応=自前RAG構築とその限界
「RAGの仕組みは分かった。じゃあ自社でも作ってみよう」となったとき、何が必要になるか。一般的な自前RAG構築のステップと、そこで生じる現実的な難しさを見ていきます。
自前RAG構築の基本ステップ
自社でRAGシステムを構築する場合、典型的には次のような工程を踏みます。
①ナレッジベースの設計:対象とする文書の範囲・アクセス制御の方針を定める
②データの取り込みとインデックス化:PDFやWordから文章を抽出し、ベクトル化してベクトルデータベースに格納する
③検索コンポーネントの実装:質問から関連文書を取得するセマンティック検索の仕組みを作る
④LLM連携とプロンプト設計:検索結果をLLMに渡し、回答を生成させるパイプラインを組む
⑤アシスタントとしての提供:ユーザーが使えるチャットインターフェースを用意する
⑥精度チューニングとガバナンス:継続的に回答品質を評価し、検索精度・回答の安全性を改善する
自前構築の難しさ
これらの工程を見ただけでも分かるとおり、自前RAG構築は単一の技術ではなく「複数のコンポーネントの組み合わせ」です。各層で技術選定と運用設計が必要になり、難易度は決して低くありません。
- 複数コンポーネントの組み合わせ:ベクトルDB、検索エンジン、LLM、ガードレール、認証基盤など、複数の要素を組み合わせる必要がある
- 運用負荷:文書が追加・更新されるたびにインデックスを再構築する仕組みや、検索精度を監視する仕組みが必要
- 精度チューニング:検索アルゴリズム、チャンク分割の粒度、プロンプト設計など、調整すべきパラメータが多岐にわたる
- ガバナンス:誰がどの文書にアクセスできるか、AIが回答してよい範囲はどこまでかという統制設計が別途必要
最大の落とし穴|元データが整っていないと精度は出ない
ここまで述べた技術的な難しさよりも、もっと根本的な落とし穴があります。それは、「どれだけ仕組みを作り込んでも、元のデータが整っていなければ精度は出ない」という事実です。
社内文書をそのままナレッジベースに放り込めば、RAGが万能に答えてくれる——そんなふうには行きません。重複した古いマニュアル、矛盾する規程、何年も更新されていないFAQが混ざっていれば、RAGは誤った文書を根拠にして、自信たっぷりに間違った答えを返してしまいます。
RAGの精度は、検索エンジンやLLMの性能で決まるのではなく、AIに渡すデータの質で決まる——これが、自前で作って初めて多くの企業が直面する現実です。
4. RAGの精度を左右するのは“データ品質”
ここからが本記事で最もお伝えしたい論点です。RAG活用を成功させる企業と、PoCで止まる企業の分かれ目は、AIに渡すデータをどれだけ整えられているか、にあります。
「Garbage In, Garbage Out」の原則
古くからあるデータ処理の格言に、「Garbage In, Garbage Out(ゴミを入れればゴミが返る)」というものがあります。生成AIの時代になっても、この原則は変わりません。むしろAIは、入力された情報を一見もっともらしい形に整えて返してくれてしまうため、「ゴミが入った」ことに気づきにくくなる、というやっかいな性質があります。
重複・古い・矛盾した文書を放置したままでは、RAGは誤った根拠を拾います。これがRAG活用の最大のリスクです。
社内文書をRAGに渡すときに起こりがちなのは、こんなパターンです。
- 古い版と新しい版の規程が両方インデックスに残り、AIが古い情報を優先して回答してしまう
- 部署ごとに作られたマニュアルの記述が矛盾しており、AIが矛盾した答えを行き来する
- 項目名・用語の表記揺れにより、関連文書をうまく検索できない
- アクセス権限が曖昧で、本来見られない情報がAIの回答に紛れ込む
これらは、技術ではなくデータ整備の問題です。LLMをどれだけ高性能なものに切り替えても解決しません。
構造化データと非構造化データの両方を“整った状態”でAIに渡す
もう一つ大事なのが、RAGで扱うデータは非構造化データ(文書)だけではない、という点です。質の高いAIアシスタントを実現するには、文書と並んで、社内の数値・分析データ(構造化データ)も、整った状態でAIに渡せる必要があります。
例えば「今四半期の売上トップ3製品の規格情報を教えて」という質問には、構造化データ(売上ランキング)と非構造化データ(製品仕様書)の両方を組み合わせる必要があります。どちらか一方だけ整っていても、業務で使える回答にはなりません。
つまりRAGの土台に必要なのは、構造化データと非構造化データの両方を統合し、品質を担保し、ガバナンスを効かせた状態にする「データ基盤」そのものです。AI活用の精度は、AIモデル選定よりも、その手前のデータ基盤の整備度合いに大きく左右されます。
そしてもう一つ忘れてはならないのが、「整ったデータをAIに渡す手段」も同じくらい重要だという点です。どれだけデータを整備しても、それをAIから安全に・統制された形で参照できる仕組みがなければ、業務利用には踏み切れません。つまり、信頼できるAIアシスタントを実現するには、データを「整える」だけでなく、それをAIへ「安全につなぐ」仕組みもセットで考える必要があります。
この「安全につなぐ」を担う仕組みとして近年注目されているのがMCP(Model Context Protocol)です。詳しくは別記事「AIに社内のデータ・システムを安全につなぐには?MCPの仕組みと選び方」で解説しています。
5. Qlikによる解決——Qlik Answers+データ基盤
ここまで見てきたように、RAGの社内活用を成功させるには「すぐ使えるRAGの仕組み」と「整った信頼できるデータ基盤」の両方が必要です。この2つを組み合わせて提供できるのが、Qlikのソリューションです。
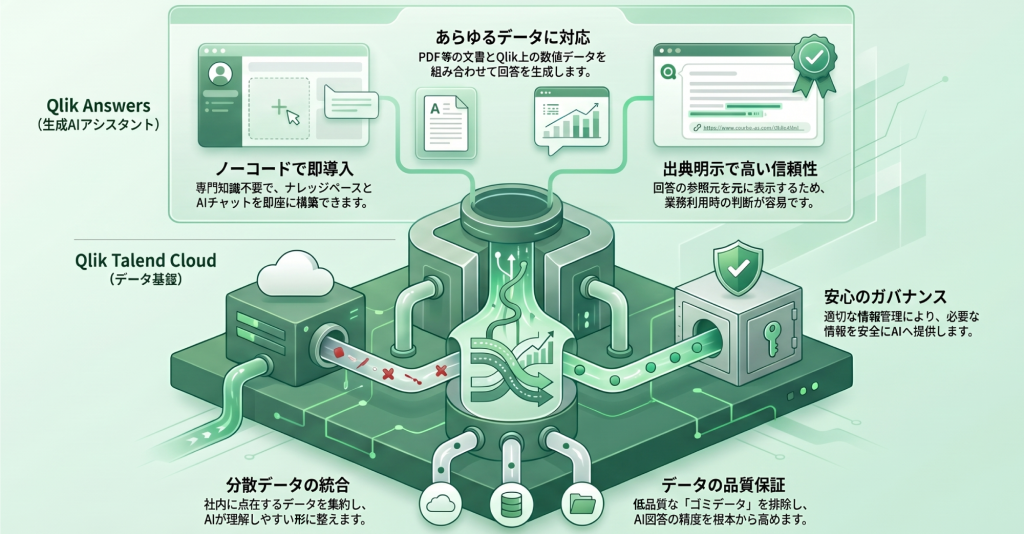
Qlik Answers——RAGベースの生成AIアシスタント
Qlik Answers は、Qlik社が提供する生成AIアシスタントです。
- プラグアンドプレイ/ノーコードで導入できる:ベクトルDB・検索エンジン・LLMといった複数コンポーネントを自前で組み合わせる必要がなく、ノーコードでナレッジベースとアシスタントを構築できます。自前構築で発生する技術的負荷を一気に取り除けるのが大きなメリットです。
- 構造化データと非構造化データの両方に対応:PDF・Word・HTML・テキストといった非構造化データに加え、Qlik分析アプリケーション上の構造化データもナレッジソースとして組み合わせて活用できます。文書と数値の両方を踏まえた回答が可能になります。
- 出典つきで回答する仕組み:Qlik Answersは、AIエージェントが回答を作成する際に参照した情報源を表示できます。回答の出所が透明化されるため、業務での利用判断がしやすくなります。
- セマンティック検索とRAGによる回答生成:ユーザーの質問の意味を理解する検索(セマンティック検索)と、関連情報をもとに回答を生成するRAGの仕組みを内包しています。
Qlik Talend Cloud——RAGの“土台”となるデータ基盤
Qlik Answers の効果を最大化するには、その手前のデータ基盤を整えておくことが欠かせません。ここを担うのが Qlik Talend Cloud です。
- 社内に散在するデータの統合:複数のシステム・場所に分散したデータを統合し、AIが扱いやすいクリーンな状態に整えます。
- AI向けのデータ信頼性評価:AIに渡すデータの品質・信頼性を客観的に評価する仕組みを備えており、「ゴミデータ」がAIに渡らないように土台を作れます。
- ガバナンスを効かせたデータ提供:誰がどのデータを参照できるかという統制を効かせた状態で、AIに必要な情報を提供できます。
一般的な社内AI検索の仕組みの中には、文書をインデックス化して検索できるようにするところまでで止まり、その手前にあるデータの品質や統合まではカバーしないものも少なくありません。Qlikは、「すぐ使えるRAG(Qlik Answers)」と「データを整える基盤(Qlik Talend Cloud)」を一気通貫で提供できる点に強みがあります。
インサイトテクノロジーによる導入・データ整備支援
インサイトテクノロジーは、30年以上のデータベース技術のナレッジを基盤に、Qlik AnswersおよびQlik Talend Cloudの導入と、その土台となる社内データの整備までを一貫してご支援しています。「とりあえずAIアシスタントを入れて終わり」ではなく、「業務で使える精度のAI活用」までを伴走するパートナーとしてご利用いただけます。
まとめ
- 汎用AIは社内固有・最新の情報を知らず、出典も示せないため、業務利用には限界がある。
- RAG(検索拡張生成)は、社内データを検索しその情報をもとにAIが回答することで、汎用AIの限界を超える仕組み。出典つき回答により業務での検証も可能。
- 自前でRAGを構築するには複数コンポーネントの組み合わせ、運用負荷、精度チューニング、ガバナンス設計など、多くの技術的ハードルがある。
- そして最大の落とし穴は、元データの品質。AIに渡すデータが整っていなければ、どれだけ仕組みを作り込んでも精度は出ない。
- RAGの精度を本当に決めるのは「データ品質」。構造化データと非構造化データの両方を、整い・統合・ガバナンスの効いた状態にする“データ基盤”が必要。
- Qlik Answers(RAGベースのAIアシスタント)とQlik Talend Cloud(データ基盤)を組み合わせることで、社内データの整備からAI活用まで一気通貫で実現できる。
社内文書を生成AIで活かしたいとお考えの方へ
インサイトテクノロジーでは、Qlik AnswersとQlik Talend Cloudを活用した、社内データの整備からAI活用までを一貫してご支援しています。「自社の文書資産をAIで活かしたい」「社内向けAIアシスタントを企画しているが、何から始めればいいか分からない」といった段階からのご相談を承っています。
▼ Qlik Talend Cloudについて詳しく見る
https://www.insight-tec.com/products/qlik-talend-cloud
▼ サッポロホールディングス株式会社のQlik Talend Cloud活用事例を見る
https://www.insight-tec.com/case/sapporohd_0037
▼ AIデータ活用支援についてまず相談する
https://www.insight-tec.com/products/qlik-talend-cloud/#f

