Insight Masking(旧名称:Insight Data Masking)

大規模言語モデルを活用した、個人情報を
速く・正確に匿名化するデータマスキングソフトウェア
速く・正確に匿名化するデータマスキングソフトウェア
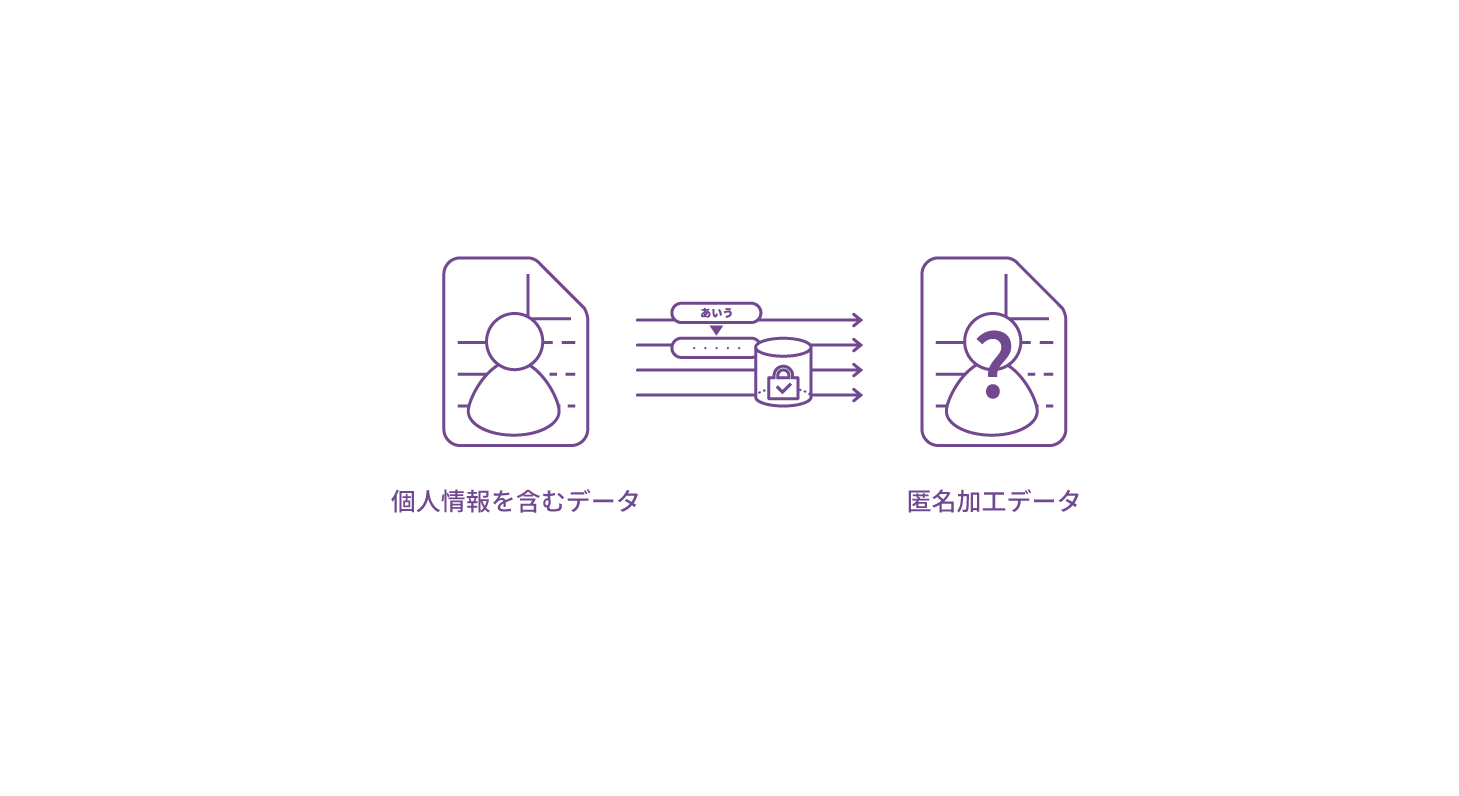
個人情報などの機密情報をマスキングで匿名化。
非本番環境へのデータコピー、環境移行のテスト、データ分析などの場面で、
情報漏洩のリスクを低減する。
非本番環境へのデータコピー、環境移行のテスト、データ分析などの場面で、
情報漏洩のリスクを低減する。
マスキングで匿名化すべきデータを特定するための事前調査や、
匿名化データ生成のための設計・開発にかかる膨大な工数を削減
匿名化データ生成のための設計・開発にかかる膨大な工数を削減
Insight Maskingの特徴
01 日本語に対応したデータマスキング、豊富なマスキング設定ルールにより様々な利用シーンに対応
データのユニーク性、参照性・整合性などデータの論理的特性をそのままにマスキング。データの種類・分布などのデータの統計的特性も維持したままのテストデータを生成します。
テストデータ生成
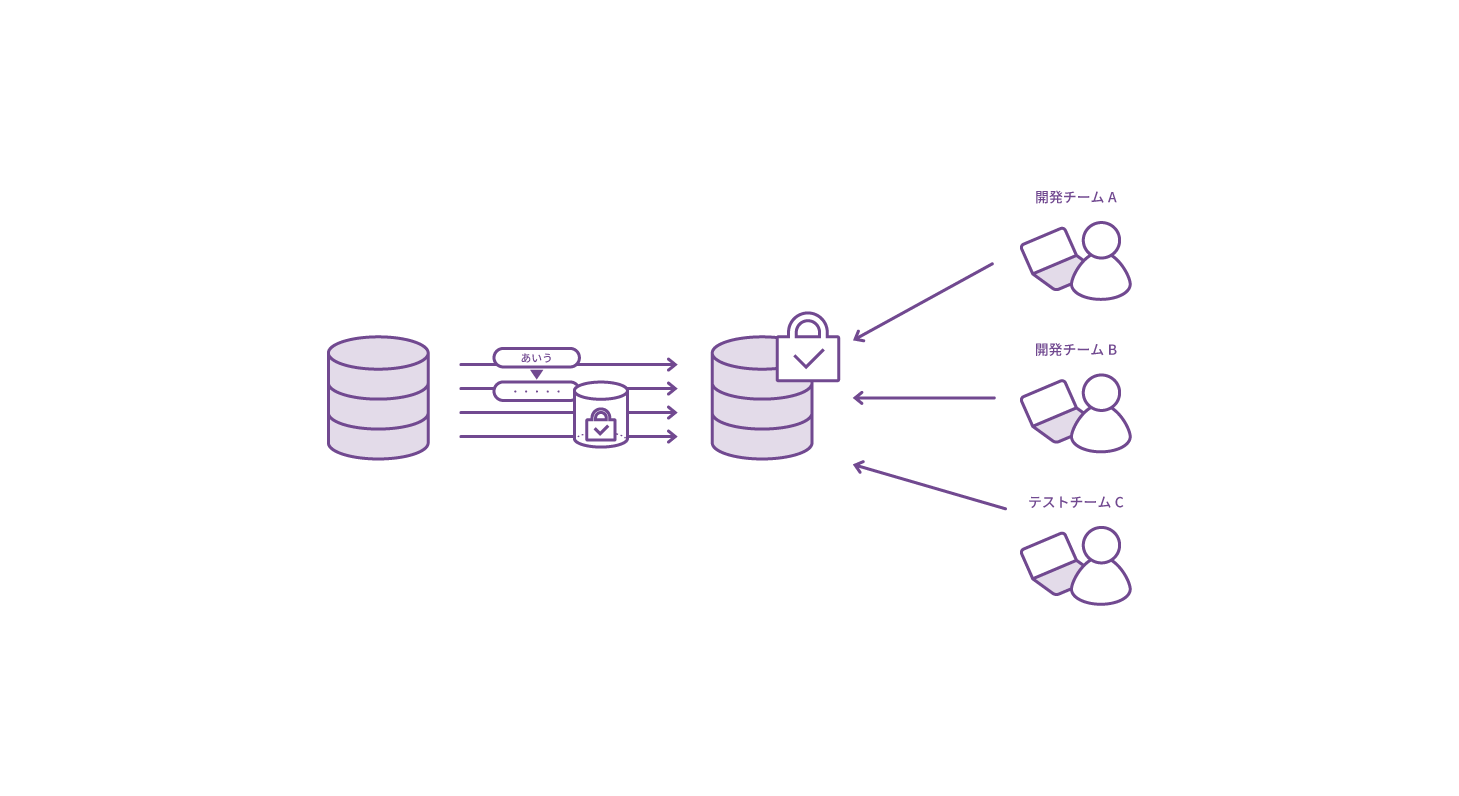
不十分なデータでのテストによる不具合の防止や短期間でのデータ準備、性能評価に利用可能なテストデータとして、開発サイクルの効率化に貢献します。
データのクラウド移行検証
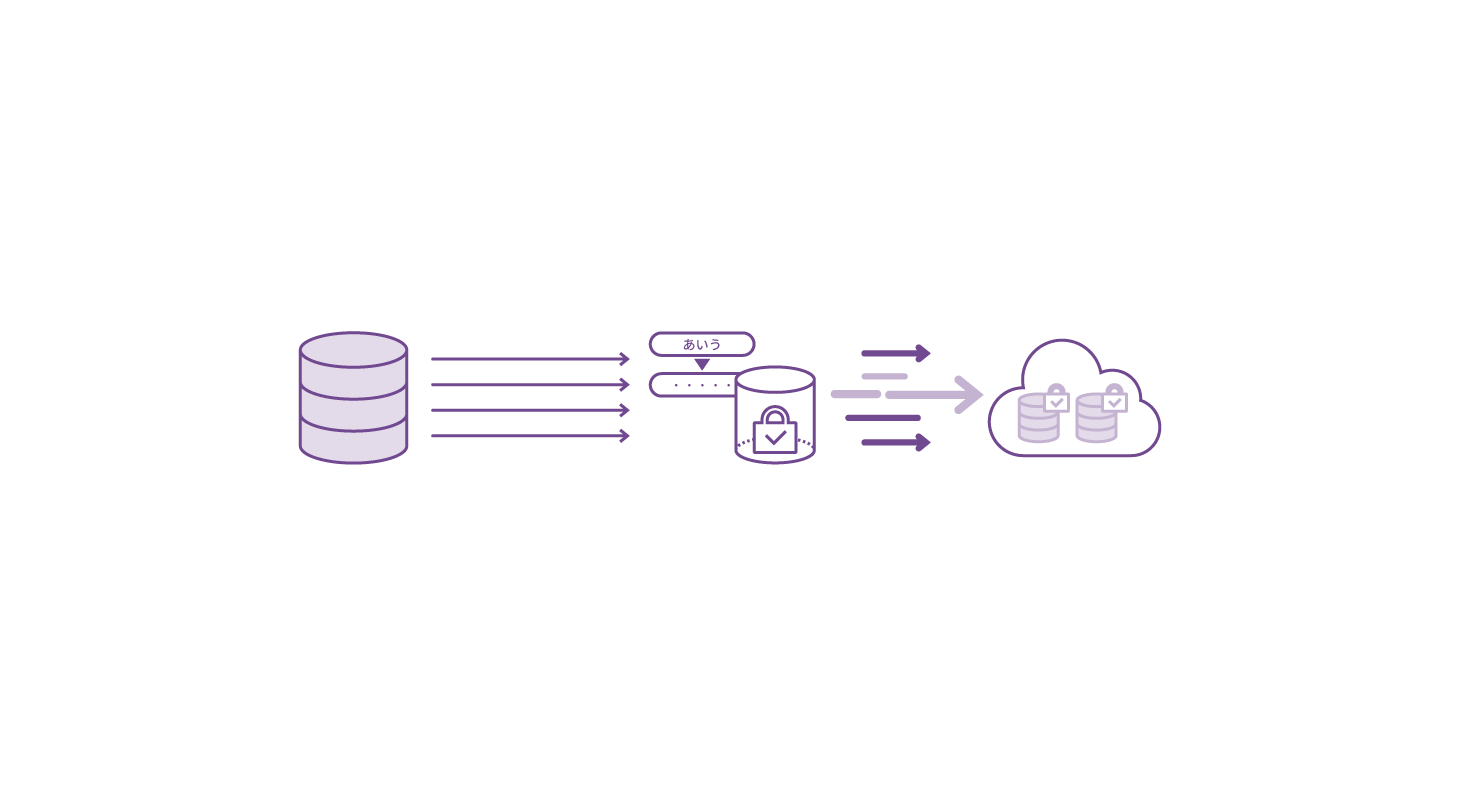
データ持ち出し時にセキュリティを担保しながら機能面のテストや性能評価を行うことができ、クラウド移行準備の工数削減に貢献します。
分析データの準備
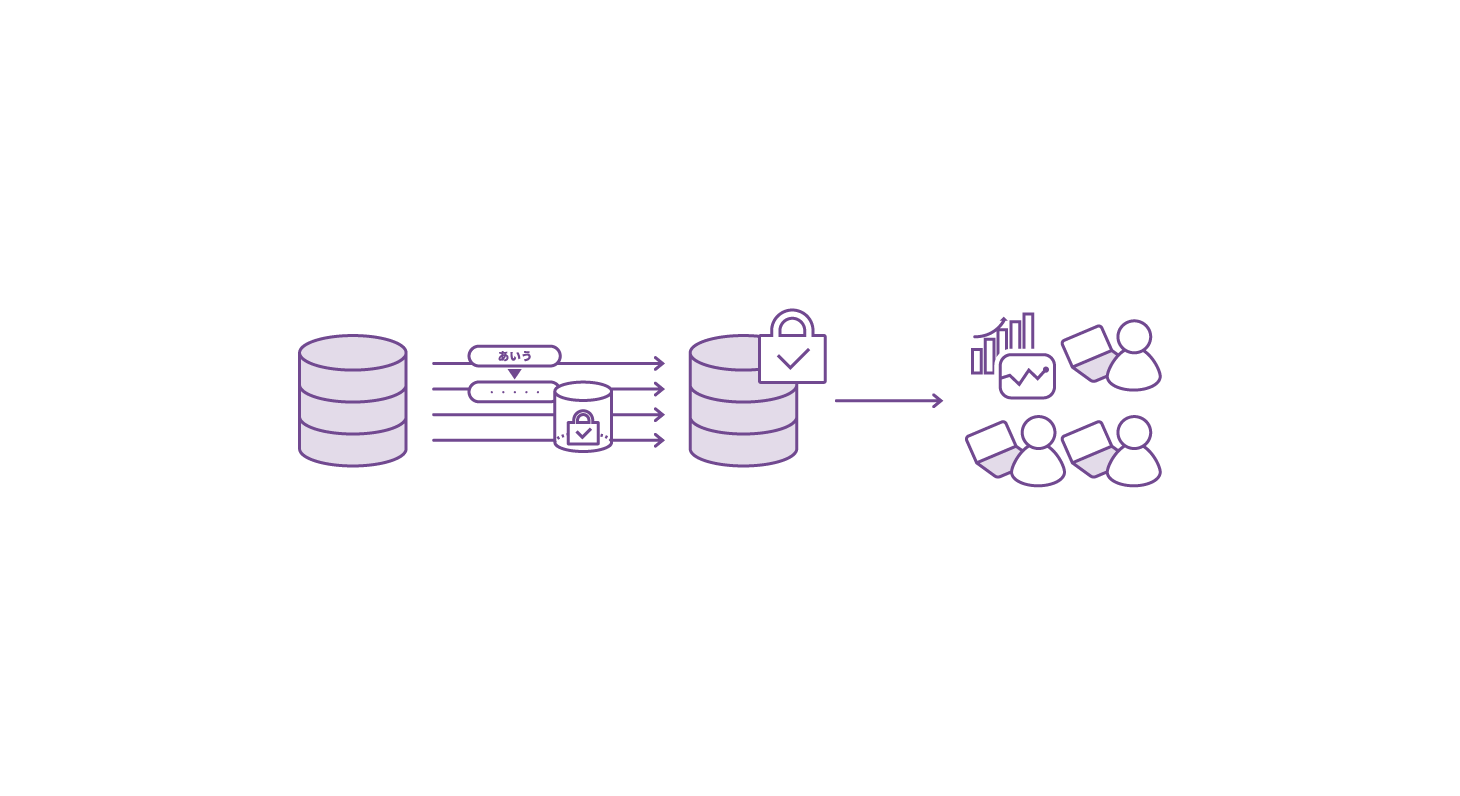
個人情報を含むデータのマスキング、更にマスキングデータ作成フローの自動化により、セキュリティリスクを抑止。ビジネスユーザーが利用できる分析用データを作成できます。
サマリー
- DB移行時に元データの特徴そのままにテストデータで検証が可能
- クラウド移行時のPoC(事前検証)におけるセキュリティの担保
- 個人情報を匿名加工したデータを協力企業や自社でのデータ分析の現場に提供可能
02 日本語に最適化されたAIエンジンによる個人情報の自動抽出
自社開発の高性能AIエンジンで日本語(ひらがな、カタカナ、漢字)に最適化。英数字や記号など文字種を判別して、ファイルやデータベースのカラム・文章データから個人情報を自動抽出します。ユーザーが独自ルールを定義することで、より細かな抽出が可能になります。
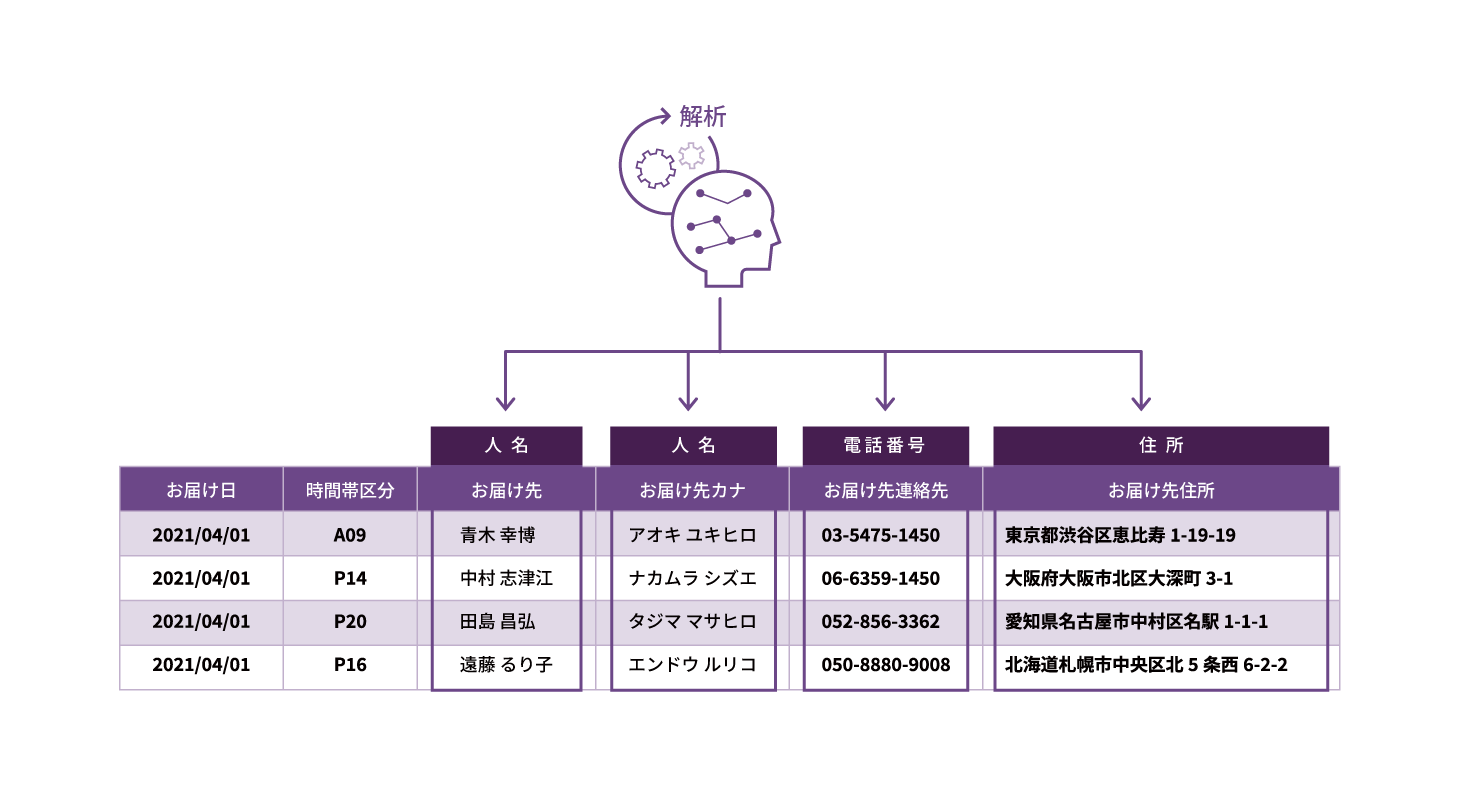
- データベースやCSVファイル等からマスキング対象のデータ項目を検出
- メール、チャット等のフリーテキストから、匿名処理の対象に該当する単語を検出
フリーテキスト(テキスト文章、メール etc.)から、該当する単語を検出
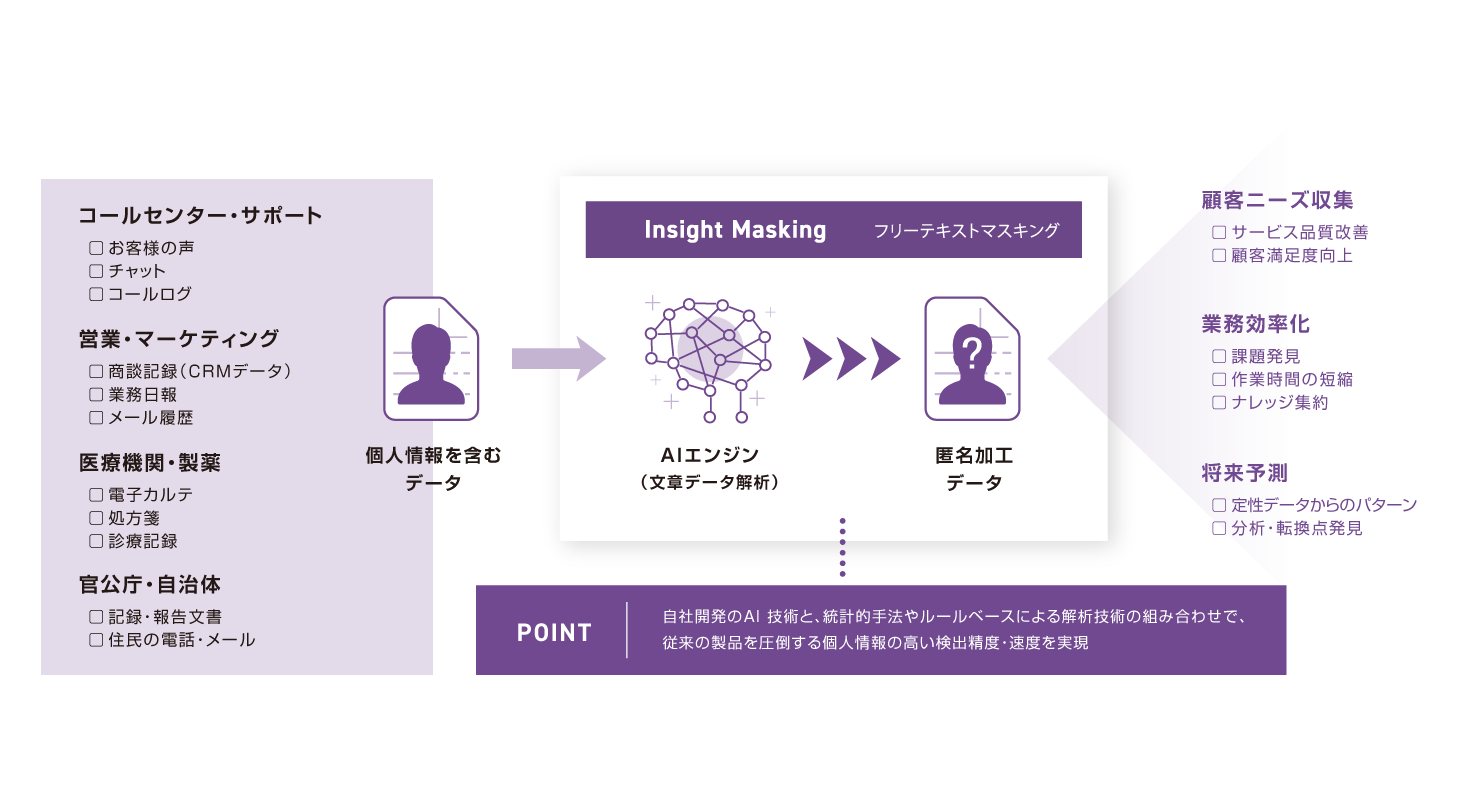
検出可能なデータ(ラベル)
実データを解析して、匿名化対象の個人情報・機密情報を検出。該当データのカラムに自動でラベル付けが行われます。
個人情報(基本)
個人名
- 氏名
- 姓/名
- ふりがな/フリガナ
住所
- 郵便番号
- 都道府県/市区町村
- 住所
- ふりがな/フリガナ
その他個人情報
- 年齢
- 生年月日
- 性別
- 電話番号
機微な情報 etc.
日本固有
- 銀行口座番号
- 運転免許番号
- マイナンバー
- パスポート番号(旅券番号)
グローバル共通
- クレジットカード番号
- メールアドレス
- パスワード
その他個人情報(機微情報)
- 会社名(勤め先/取引先)
- 法人番号
その他(ユーザー固有)
- ID属性を持つ情報
カスタマイズされた情報
その他
- ユーザーが定義した情報
(正規表現でマッチング)
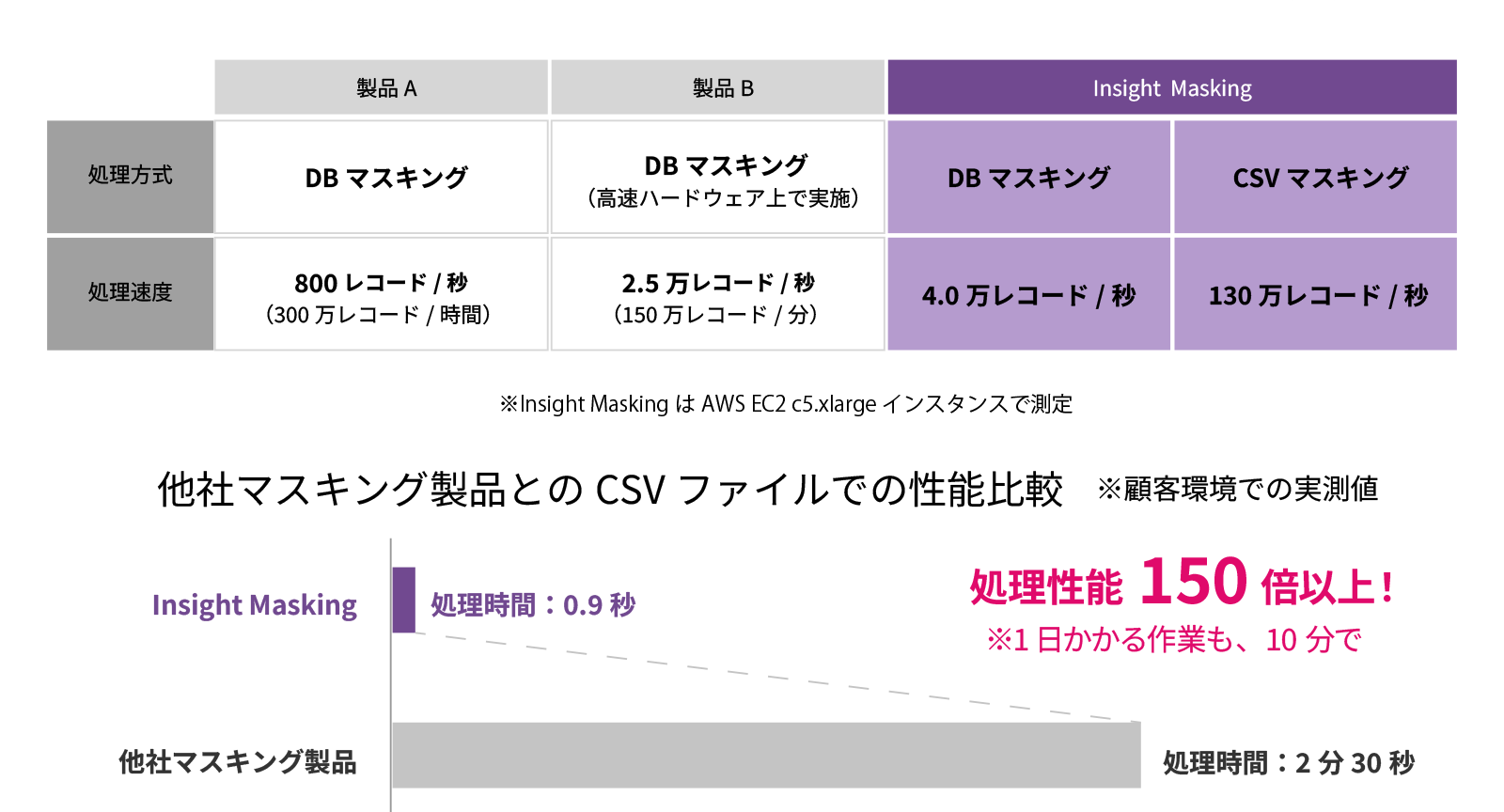
03 高速な処理性能
Insight Maskingはデータ加工処理のパラレル化により、これまで大量のマスキング処理にかかっていた膨大な時間を劇的に圧縮。データマスキングに必要な工数を削減します。
Insight Maskingの機能
日本語に最適化された高性能AIエンジンにより、匿名化候補文字列の自動検出と自然な変換で豊富なマスキング設定ルールを実現。DBのデータへの直接マスキングだけでなく、Dumpファイル、CSVやParquet、フリーテキスト(文章データ)にも対応。WebAPIによるマスキングも可能です。
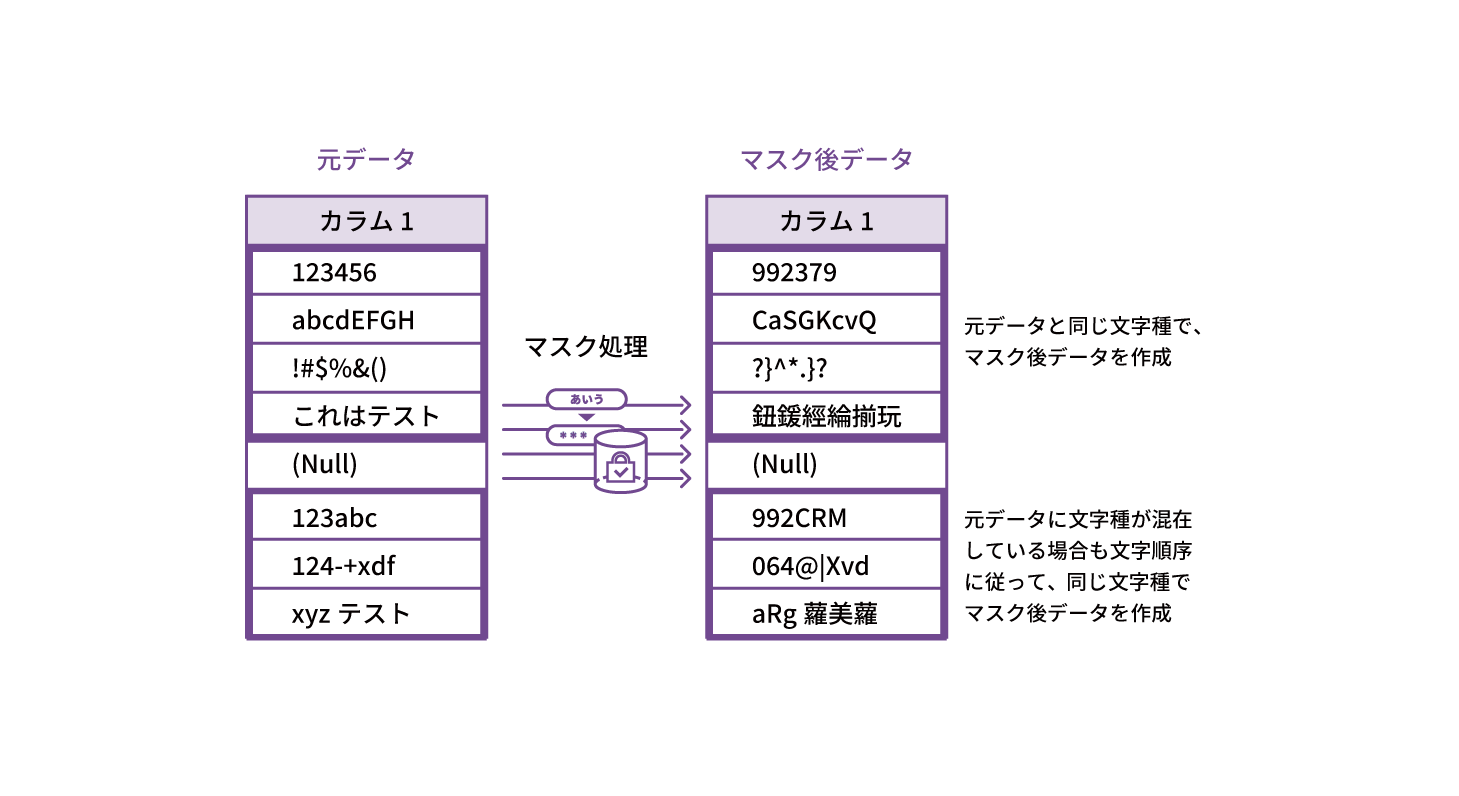
FUNCTION 01 文字種、文字長を維持してマスキング
ひらがな、カタカナ、漢字等のマルチバイト文字に対応。英数字、日本語、記号等が混在していても、元データと同じ文字種・文字数でデータを生成します。
- 半角カナ、全角数字、全角アルファベット含む
- (株)等、そのまま残したい文字列は、予約語(除外文字)として登録可能
FUNCTION 02 複数のデータ間での整合性(データモデル)を維持
システムで採番されたID等のユニーク性を保ったままのマスキングが可能です。複数テーブル間での関係性(参照整合性)を崩しません。

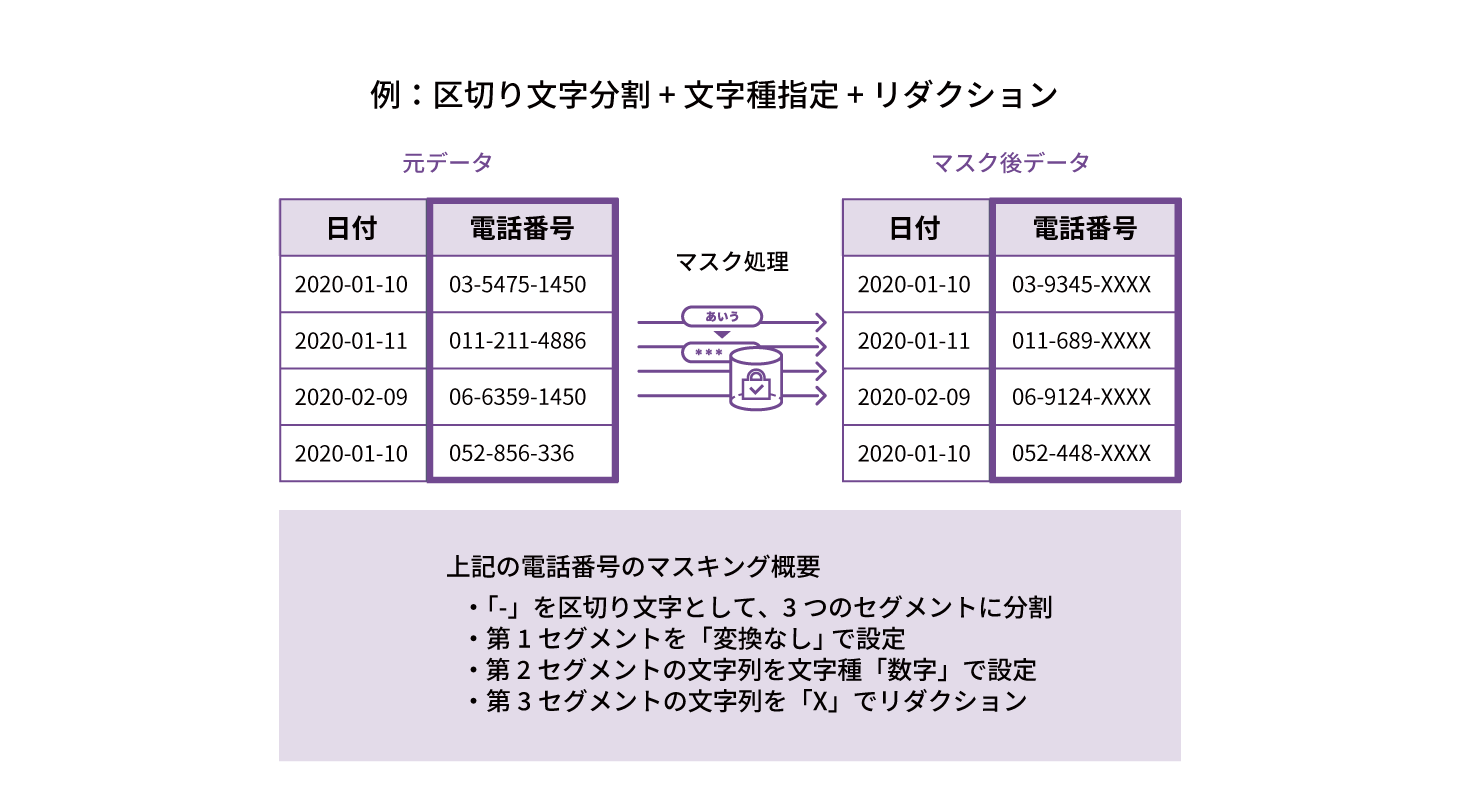
FUNCTION 03 特定箇所(セグメント)を指定してマスキング
電話番号、郵便番号、クレジットカード番号などに対して、ハイフンなどを区切り文字に選んでセグメントを指定可能。分割された文字列毎にマスキング処理の方法を設定することができます。
FUNCTION 04 独自の辞書でマスキング
ユーザー作成の期待値データを格納した辞書ファイルを用意すれば、期待値データで置換が可能です。(人名を格納した辞書ファイルを準備し、氏名データを置換など)
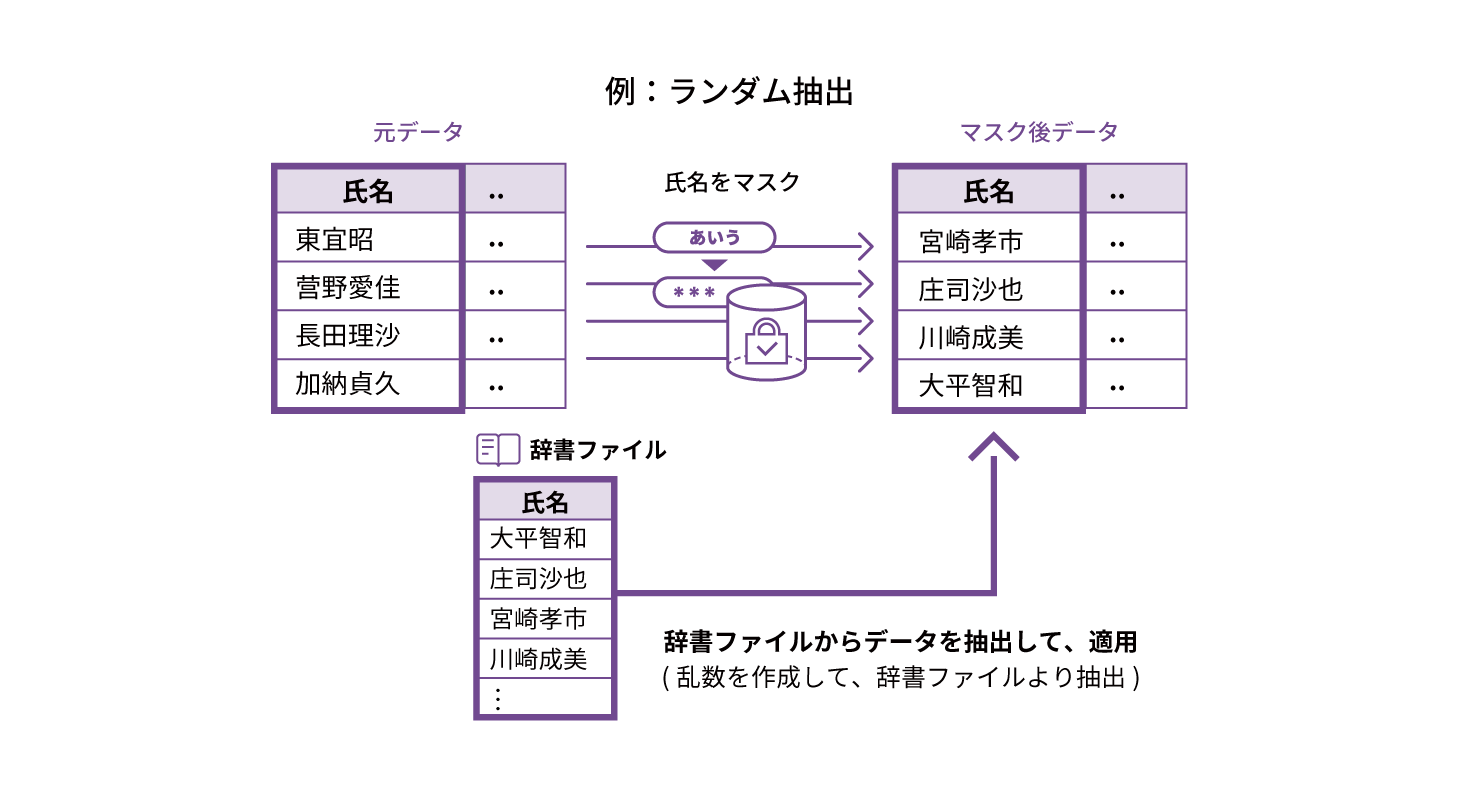
FUNCTION 05 再現性を保ったマスキング
マスキング処理を複数回行った場合、毎回同じ結果を得られるようにすることも、実施毎に異なる結果を得られるようにすることも可能です。(日々追加される業務データなどの差分データのマスキングに利用可能)
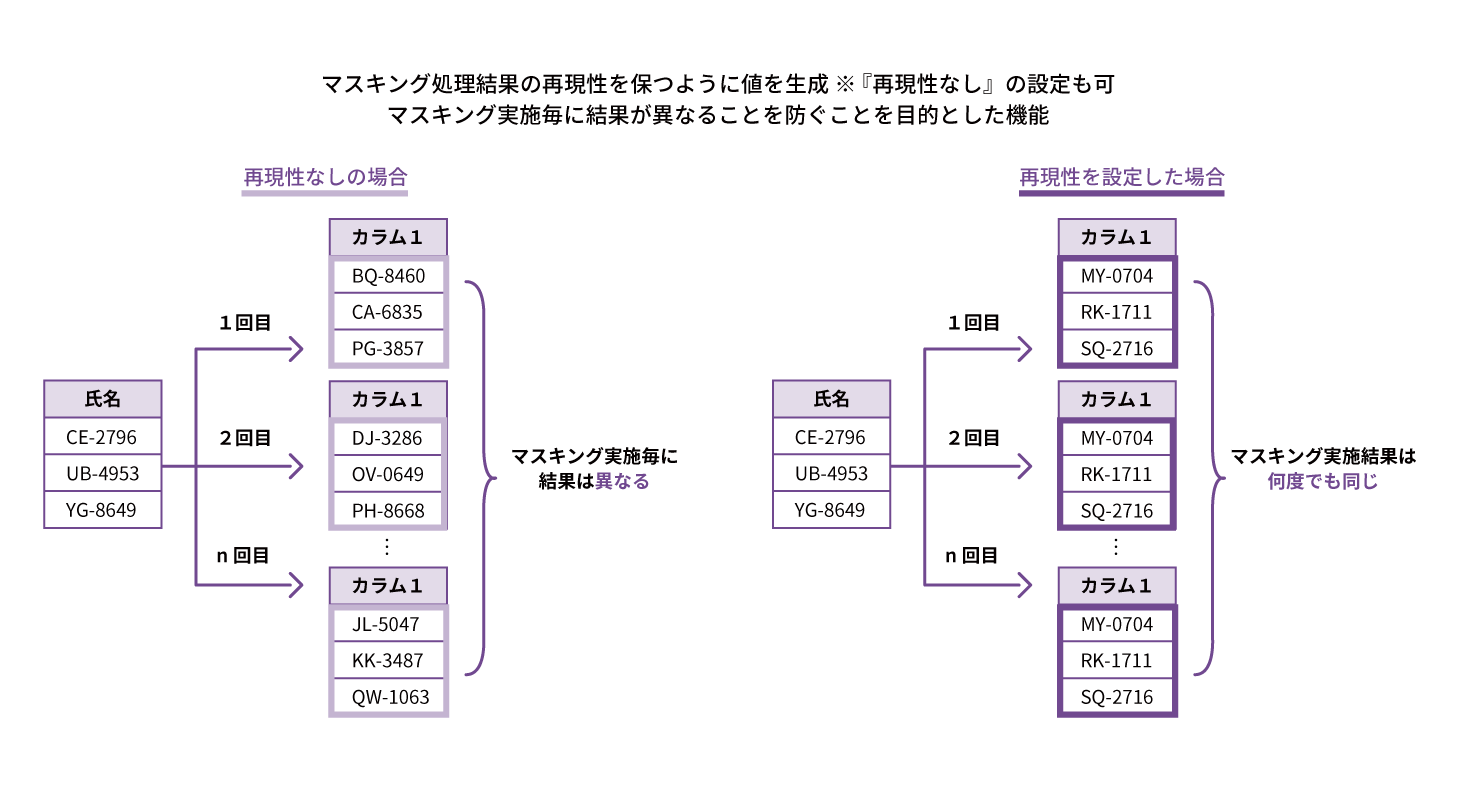
FUNCTION 06 AIでフリーテキストから自動検出
メール、電話のコールログのようなフリーテキスト(文章データ)からマスキング対象に該当する単語を自動検出。チャットボット等のデータや業務システムの履歴データ、自由記述欄のテキストなどの匿名化対応が可能です。
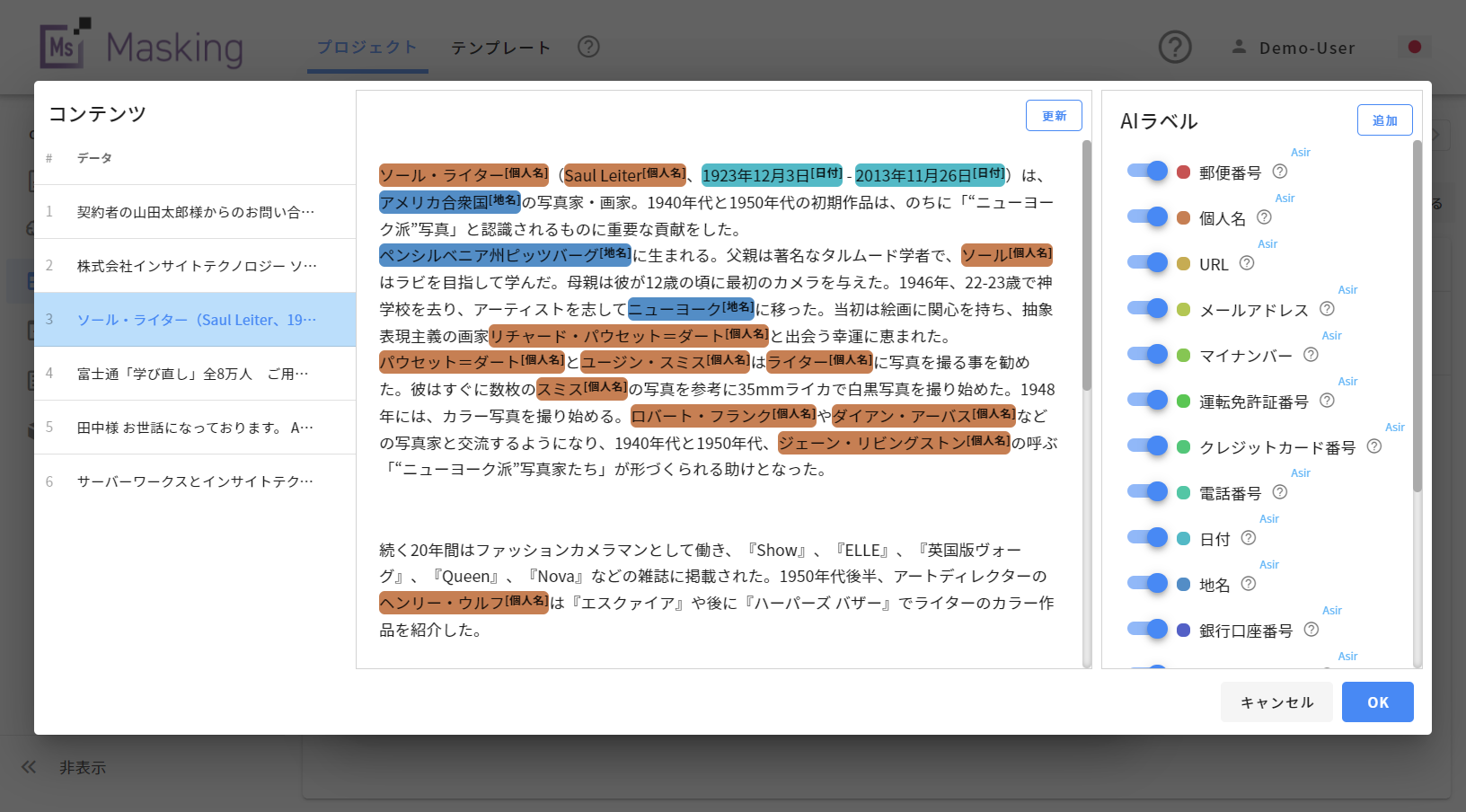
フリーテキストのGUI設定のイメージ
※ルールベースに加え、NER(固有表現抽出)自然言語処理でテキスト解析を行います。
NER : Named Entity Recognition
Insight Maskingの
対応環境
Insight Masking は OS(Oracle Linux 8)および各種ソフトウェアを組み合わせた仮想アプライアンスとして提供しています。

| 仮想アプライアンス | VMware ESXi / AWS EC2 / Azure VM |
|---|---|
| CPU | 2 vCPU 以上 |
| メモリ | 8 GB |
| ディスク | 50 GB 以上 |
※ Qlik Replicateとの連携では、データソースはQlik Replicateのサポート対象に従います。 ※ 稼働環境に対する詳細情報は、お問い合わせください。
Insight Maskingが
解決する課題
theme
01
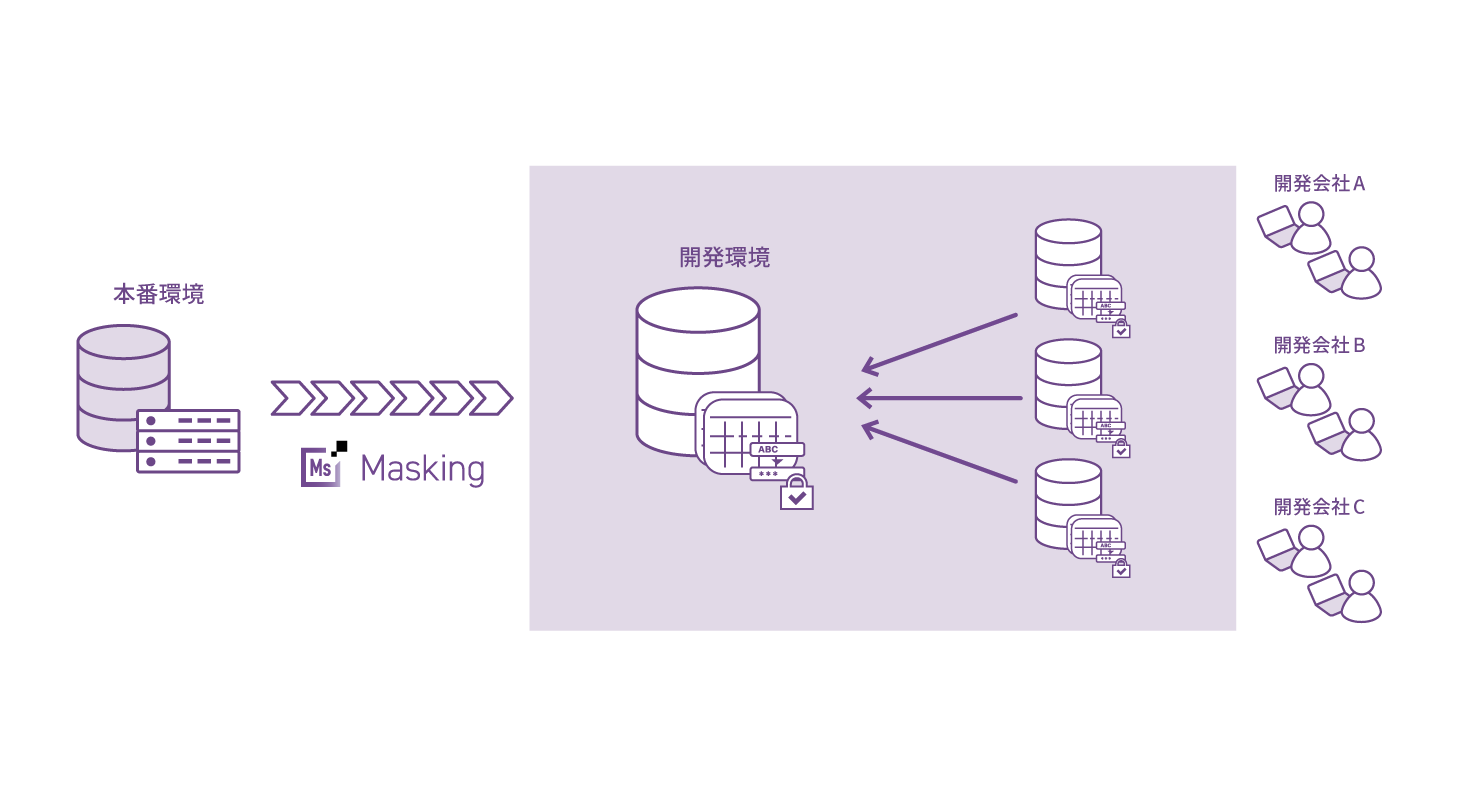
本番同等のテストデータでシステム開発のスピードと開発品質を向上したい
システム開発のスピードと品質の向上にあたり、テストデータの作成工数とその品質が課題となっています。システム開発の現場ではテストデータを作成する手段としてダミーデータや自前で加工した本番環境のデータを利用することがあります。しかし、ダミーデータを利用する場合、本番データ同等のパフォーマンス検証は難しく性能評価の有効性が担保できません。また、自前で加工した本番環境のデータを利用する場合も、テーブル間の関係性を維持するなど本番同様のデータ作成は難しく、準備の工数も必要です。製品導入による解決を模索している企業もありますが、多くの現場では効率化を実現できていないのが現状です。Insight Maskingは高速・高精度に本番同等のテストデータを作成でき、システム開発のスピードと品質を向上します。
theme
02
情報漏洩のリスクから社員が自由にデータを分析できない
複数のユーザーや事業者がアクセスするデータ分析基盤において、機密情報や個人情報の情報漏洩リスクのため、社員が自由にデータ分析を行うことができず課題となっています。また、クラウド上でデータ分析基盤を構築したい企業のうち、セキュリティが厳格な金融機関などでは、匿名化されていない生データをクラウド上に連携したり、リモートで取り扱うことができない規制があり、事前のデータマスキングが必須となっています。
情報セキュリティマネジメントの国際規格ISO/IEC
27001が2022年に改訂されたことで、PII(personally identifiable
information)を含む機密データの管理策へデータマスキングの対応が明記されました。外部環境への機密データ露出を防ぐデータマスキングの重要性は近年ますます高まり、その対策は企業にとって急務の課題となっています。安全なデータ活用を実現するにはデータマスキング製品を導入し、本番環境の機密情報を適切に匿名化することが不可欠です。
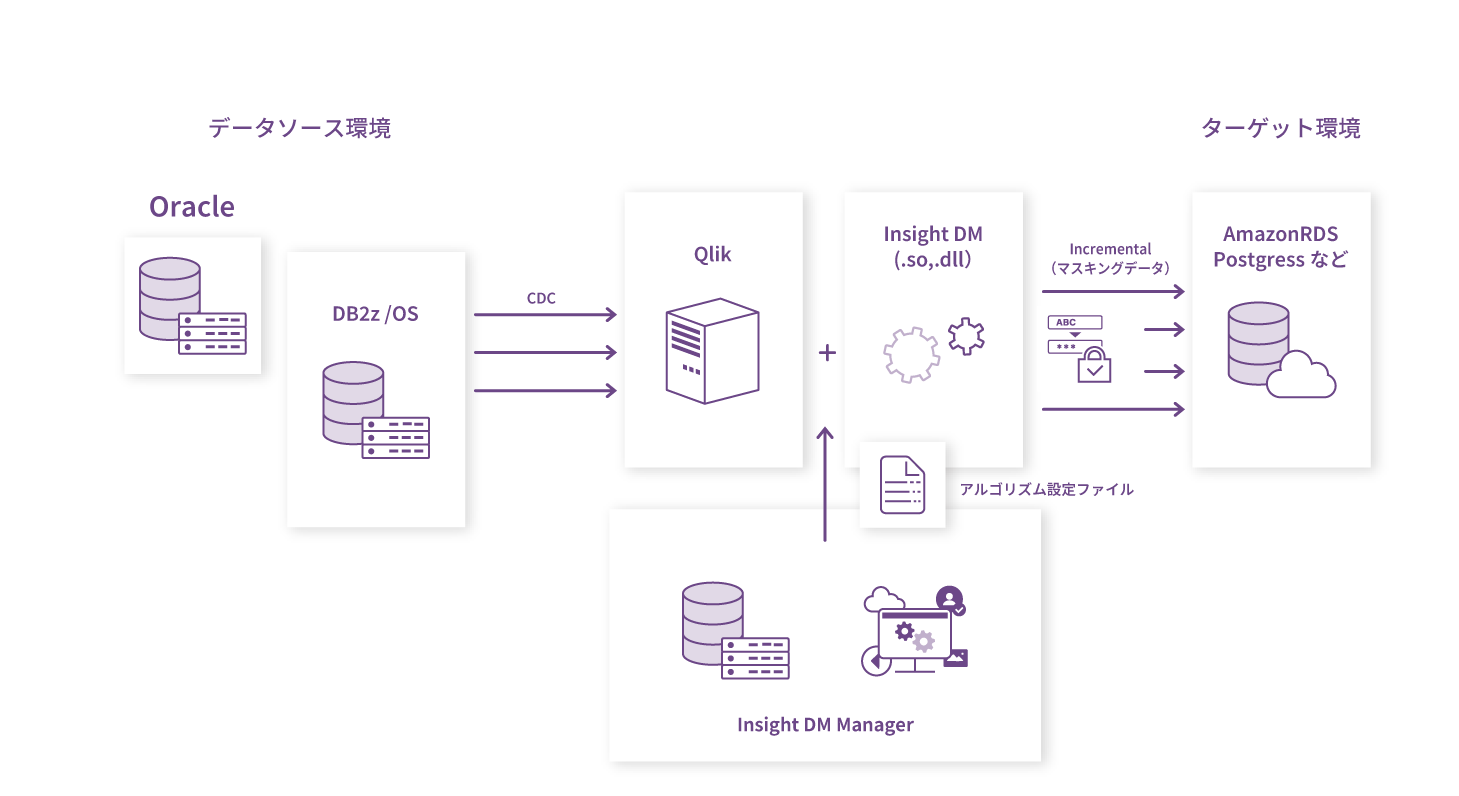
theme
03
機微な顧客向け提案書の活用、AIの活用ができない
WordやExcel、PowerpointといったMicrosoft
Office製品は、企業の現場で広く利用されています。作成されたファイル内に個人情報や機密情報が含まれることがあるため、提案書や営業資料、履歴書などを社内外へ共有や保管を行う前に匿名化する必要があります。従来は、担当者がファイルを一つひとつ確認し、個人情報を手作業で削除・置換する方法で対応していましたが、その工数や品質の担保が課題となっています。
また、ChatGPTなどの生成AIの活用が進む中、AIに業務データを学習させるには機密情報の事前の匿名化が不可欠です。しかし、生産性向上のためのAI導入が、事前のマスキングに工数がかかることで阻害されています。企業の生産性向上において、Officeファイルや新たなテクノロジーであるAIの活用を止める個人情報保護の壁への対応が急務となっています。
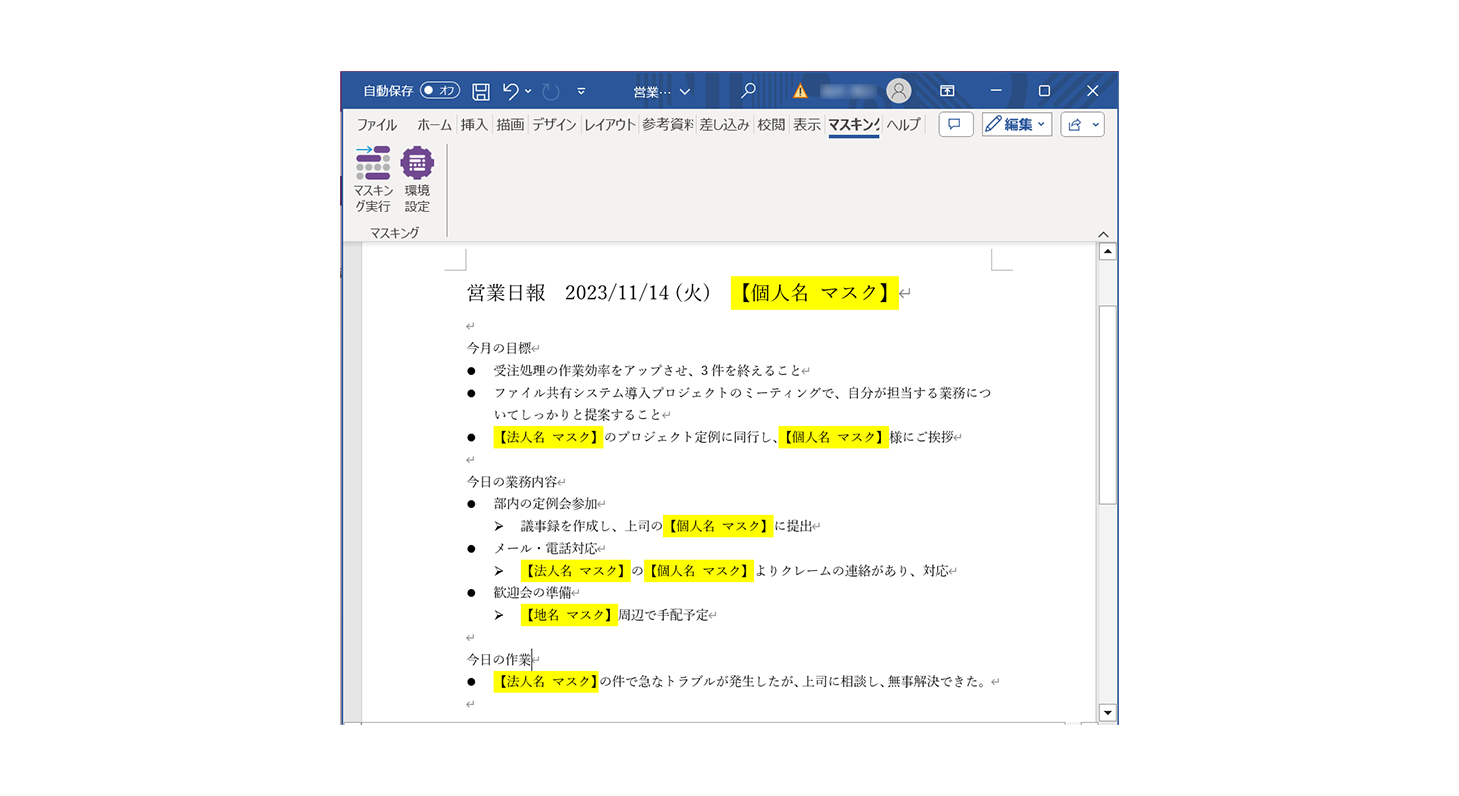
Insight Maskingの
利用シーン
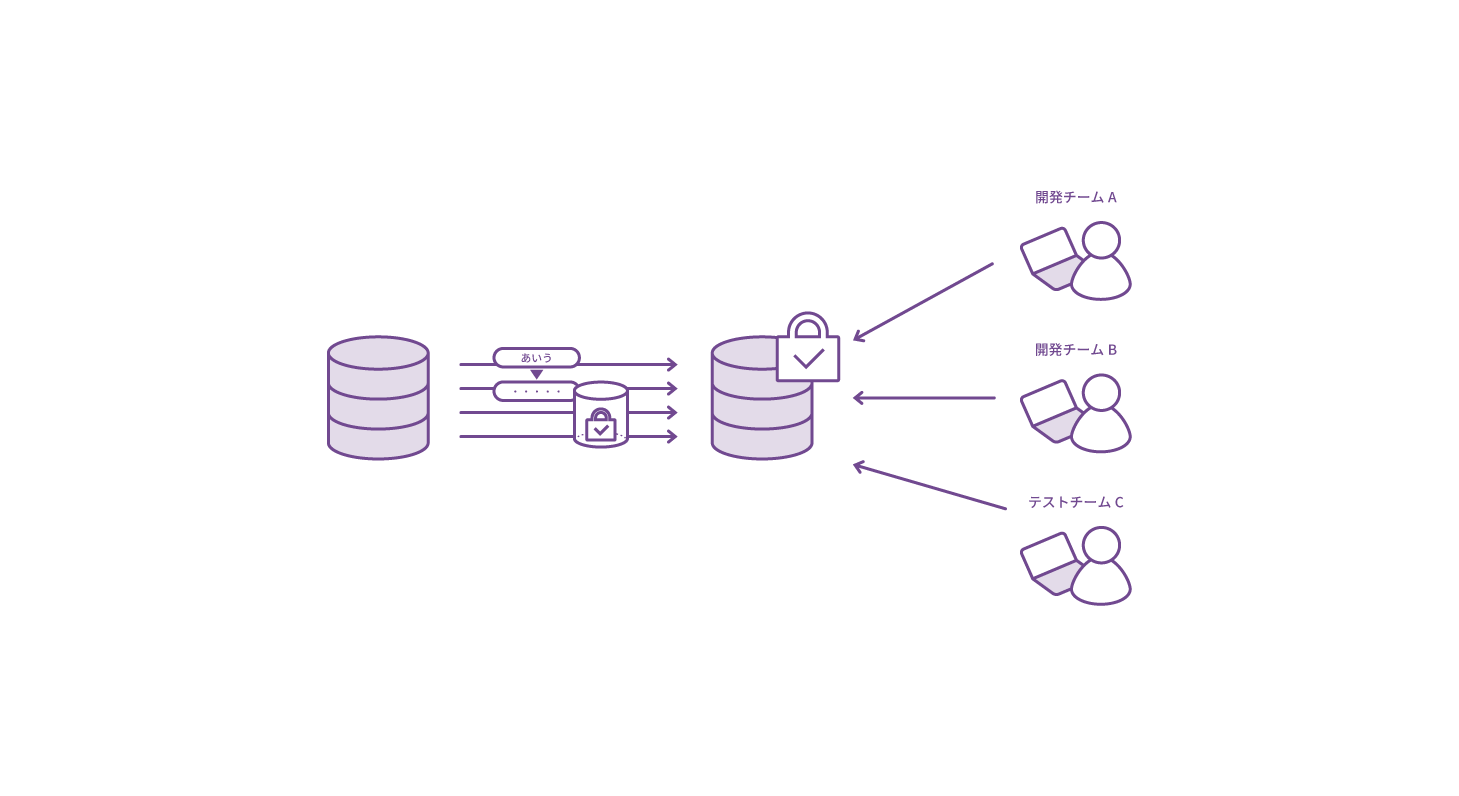
テストデータの作成
本番環境さながらのマスキングデータを活用し、システム開発時、クラウドへの移行検証時に利用
- テスト品質アップによるトラブル削減
- クラウド移行準備時、テストデータでテスト・性能評価を行い、移行作業を効率化
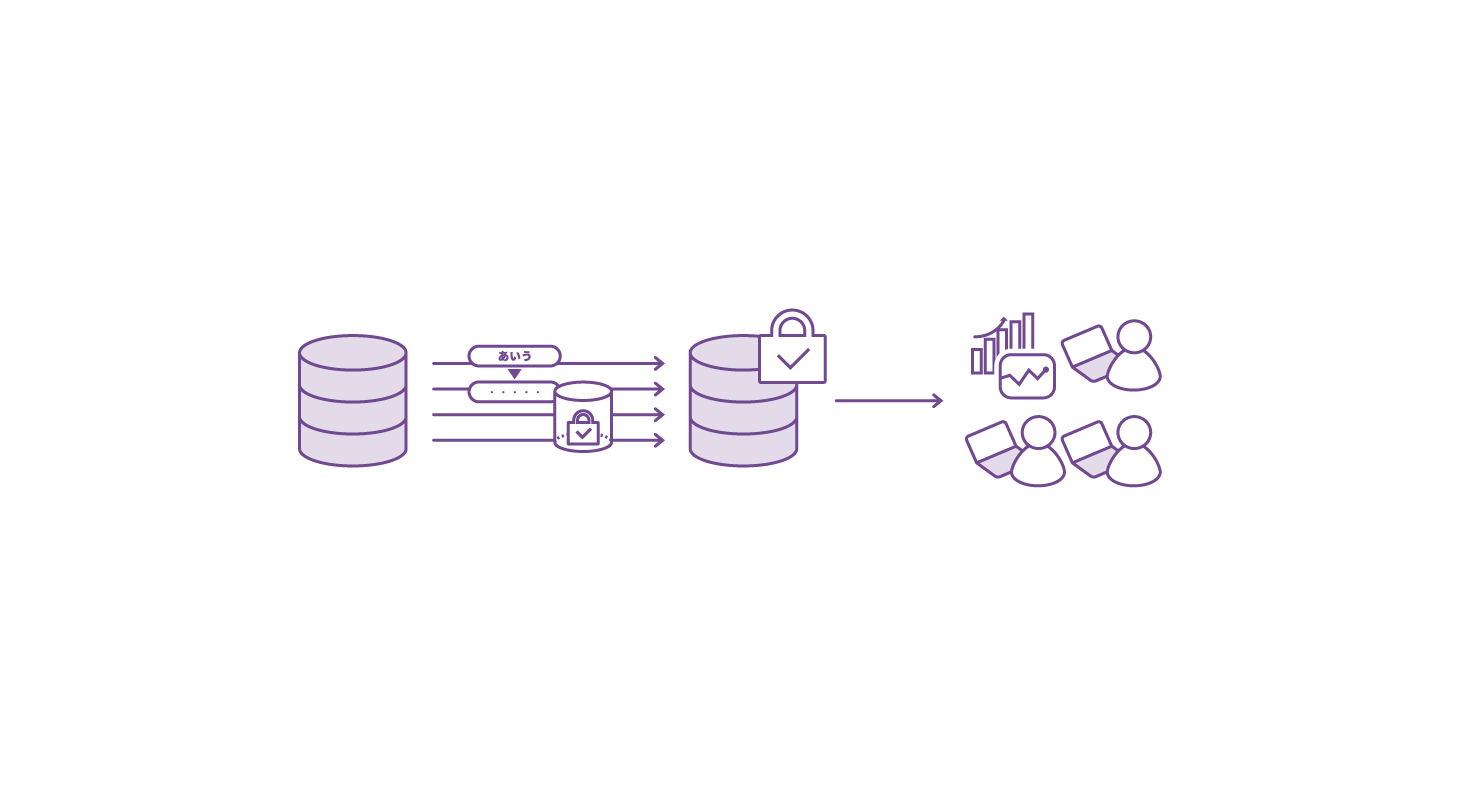
データ分析基盤における機密情報保護
複数のユーザー、事業者がデータ分析基盤のデータにアクセスする、 ISMS認証を取得する
- 匿名化・マスキング処理のパイプラインへの組込みによりデータ分析基盤での情報漏洩を防止
- 情報資産流出のリスクを防ぎながら分析のための新鮮なデータに加工
- ユニーク性・整合性が保たれた柔軟な分析が可能
文章データ内個人情報の削除と保護
コンタクトセンター・自治体等の問い合わせ履歴、調査会社のアンケート結果を他部署・他社と共有活用したい
- 文書データ中の匿名加工の自動化により、データ準備の時間削減、品質のバラつきの問題解決
- 情報資産流出のリスクを防ぎながら資料の保管・共有が可能
導入事例

株式会社NTTドコモ
顧客満足度向上のため、データ分析が急務となっていたNTTドコモ。同社では「Insight Masking」を導入し、「フリーテキストから個人情報を抽出し、リアルタイムにオンメモリでマスキングする」ことに挑戦した。導入の決め手となったのは、顧客視点に立脚したインサイトテクノロジーの迅速な開発と手厚いサポート体制だった。

note株式会社
noteではInsight Maskingによって、月に20時間以上が必要だったマスキング作業工数を数分に削減。個人情報を保護しながら、生成AIによる問い合わせ分類の自動化を実現できた。

SBI生命保険株式会社
Insight MaskingをAmazon Auroraの分析基盤に採用。マスキング処理を自動化できた上に、削減することができた。また、業務システム、分析基盤ともに同じマスキング製品を使用したことで全社的なセキュリティレベルも統一できた。

